相信读者们早都听说过了 Arch Linux 的名声,笔者也从接触 Arch Linux 起就被他所具有的特性吸引.
本文中将讲述从 Arch Linux Live CD 中安装 Arch Linux 的方法.本文中假设读者已经完成了 下载、验证 Arch Linux 安装镜像以及将 Arch Linux 安装镜像写入物理介质并使用其介质以 UEFI 模式下完成引导,启动欲安装 Arch Linux 的设备的步骤.如有读者对该部分的操作方式存在疑问,请查阅 Installation guide 获得更多信息.
连接网络
Arch Linux 安装过程必须连接网络.在以 UEFI 模式启动至 Arch Linux 安装环境后,首先要做的便是连接网络.因在「Arch Linux 安装环境」中连接 WiFi 较为麻烦,笔者推荐一下两种方式在「 Arch Linux 安装环境」中连接网络,读者任选其一即可:
Clang Thread Safety Analysis is a C++ language extension which warns about potential race conditions in code. The analysis is completely static (i.e. compile-time); there is no run-time overhead. The analysis is still under active development, but it is mature enough to be deployed in an industrial setting. It is being developed by Google, in collaboration with CERT/SEI, and is used extensively in Google’s internal code base.
Thread safety analysis works very much like a type system for multi-threaded programs. In addition to declaring the type of data (e.g. int, float, etc.), the programmer can (optionally) declare how access to that data is controlled in a multi-threaded environment. For example, if foo is guarded by the mutex mu, then the analysis will issue a warning whenever a piece of code reads or writes to foo without first locking mu. Similarly, if there are particular routines that should only be called by the GUI thread, then the analysis will warn if other threads call those routines.[3]
Valgrind is an instrumentation framework for building dynamic analysis tools. There are Valgrind tools that can automatically detect many memory management and threading bugs, and profile your programs in detail. You can also use Valgrind to build new tools.
The Valgrind distribution currently includes seven production-quality tools: a memory error detector, two thread error detectors, a cache and branch-prediction profiler, a call-graph generating cache and branch-prediction profiler, and two different heap profilers. It also includes an experimental SimPoint basic block vector generator. It runs on the following platforms: X86/Linux, AMD64/Linux, ARM/Linux, ARM64/Linux, PPC32/Linux, PPC64/Linux, PPC64LE/Linux, S390X/Linux, MIPS32/Linux, MIPS64/Linux, X86/Solaris, AMD64/Solaris, ARM/Android (2.3.x and later), ARM64/Android, X86/Android (4.0 and later), MIPS32/Android, X86/Darwin and AMD64/Darwin (Mac OS X 10.12).
spdlog:Very fast, header-only/compiled, C++ logging library.
Google Logging Library:Google Logging (glog) is a C++98 library that implements application-level logging. The library provides logging APIs based on C++-style streams and various helper macros.
unsignedlonglongquickPower(unsignedlonglong a, unsignedlonglong b) { unsignedlonglong result = 1; while (b > 0) { if (b & 1U) result *= a; a *= a; b >>= 1U; } return result; }
unsignedlonglongquickPower(unsignedlonglong a, unsignedlonglong b, unsignedlonglong n) { unsignedlonglong result = 1; while (b > 0) { if (b & 1U) { result *= a; result %= n; } a *= a; a %= n; b >>= 1U; } return result % n; }
arr01.c:3:5: warning: array index 10 is past the end of the array (which contains 10 elements) [clang-diagnostic-array-bounds] a[10] = 0; ^ ~~ arr01.c:2:5: note: array 'a' declared here char a[10]; ^
cppcheck
1 2 3 4 5 6
arr01.c:3:6: error: Array 'a[10]' accessed at index 10, which is out of bounds. [arrayIndexOutOfBounds] a[10] = 0; ^ arr01.c:3:11: style: Variable 'a[10]' is assigned a value that is never used. [unreadVariable] a[10] = 0; ^
AddressSanitizer
1 2 3 4 5 6 7 8 9 10 11 12 13 14
stack-buffer-overflow on address 0x7fffd170488a at pc 0x000000500c07 bp 0x7fffd1704850 sp 0x7fffd1704848 WRITE of size 1 at 0x7fffd170488a thread T0 #0 0x500c06 in main arr01.c:3:11 #1 0x7faeb9712b24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16 #2 0x41f12d in _start /usr/src/debug/glibc-2.33/csu/../sysdeps/x86_64/start.S:120
Address 0x7fffd170488a is located in stack of thread T0 at offset 42 in frame #0 0x500b1f in main arr01.c:1
This frame has 1 object(s): [32, 42) 'a' (line 2) <== Memory access at offset 42 overflows this variable HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork (longjmp and C++ exceptions *are* supported) SUMMARY: AddressSanitizer: stack-buffer-overflow arr01.c:3:11 in main
stack-buffer-overflow on address 0x7fffcf8cde6a at pc 0x000000500c1f bp 0x7fffcf8cde30 sp 0x7fffcf8cde28 WRITE of size 1 at 0x7fffcf8cde6a thread T0 #0 0x500c1e in main arr03.c:4:12 #1 0x7f6f26625b24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16 #2 0x41f12d in _start /usr/src/debug/glibc-2.33/csu/../sysdeps/x86_64/start.S:120
Address 0x7fffcf8cde6a is located in stack of thread T0 at offset 42 in frame #0 0x500b1f in main arr03.c:1
This frame has 1 object(s): [32, 42) 'a' (line 2) <== Memory access at offset 42 overflows this variable HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork (longjmp and C++ exceptions *are* supported) SUMMARY: AddressSanitizer: stack-buffer-overflow arr03.c:4:12 in main
arr17.c:3:5: warning: array index 6 is past the end of the array (which contains 5 elements) [clang-diagnostic-array-bounds] arr[4][6] = 0; ^ ~ arr17.c:2:5: note: array 'arr' declared here char arr[5][5]; ^ arr17.c:4:5: warning: array index 5 is past the end of the array (which contains 5 elements) [clang-diagnostic-array-bounds] arr[5][4] = 0; ^ ~ arr17.c:2:5: note: array 'arr' declared here char arr[5][5]; ^ arr17.c:5:5: warning: array index -1 is before the beginning of the array [clang-diagnostic-array-bounds] arr[-1][0] = 0; ^ ~~ arr17.c:2:5: note: array 'arr' declared here char arr[5][5]; ^ arr17.c:6:5: warning: array index -1 is before the beginning of the array [clang-diagnostic-array-bounds] arr[0][-1] = 0; ^ ~~ arr17.c:2:5: note: array 'arr' declared here char arr[5][5]; ^
cppcheck
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
arr17.c:3:8: error: Array 'arr[5][5]' accessed at index arr[4][6], which is out of bounds. [arrayIndexOutOfBounds] arr[4][6] = 0; ^ arr17.c:4:8: error: Array 'arr[5][5]' accessed at index arr[5][4], which is out of bounds. [arrayIndexOutOfBounds] arr[5][4] = 0; ^ arr17.c:5:8: error: Array 'arr[5][5]' accessed at index arr[-1][*], which is out of bounds. [negativeIndex] arr[-1][0] = 0; ^ arr17.c:6:8: error: Array 'arr[5][5]' accessed at index arr[*][-1], which is out of bounds. [negativeIndex] arr[0][-1] = 0; ^ arr17.c:6:16: style: Variable 'arr[0][-1]' is assigned a value that is never used. [unreadVariable] arr[0][-1] = 0; ^
AddressSanitizer
1 2 3 4 5 6 7 8 9 10 11 12 13 14
AddressSanitizer: stack-buffer-overflow on address 0x7ffef126b89a at pc 0x000000500c20 bp 0x7ffef126b850 sp 0x7ffef126b848 WRITE of size 1 at 0x7ffef126b89a thread T0 #0 0x500c1f in main arr17.c:3:15 #1 0x7f7522d69b24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16 #2 0x41f12d in _start /usr/src/debug/glibc-2.33/csu/../sysdeps/x86_64/start.S:120
Address 0x7ffef126b89a is located in stack of thread T0 at offset 58 in frame #0 0x500b1f in main arr17.c:1
This frame has 1 object(s): [32, 57) 'arr' (line 2) <== Memory access at offset 58 overflows this variable HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork (longjmp and C++ exceptions *are* supported) SUMMARY: AddressSanitizer: stack-buffer-overflow arr17.c:3:15 in main
arr04.c:7:5: warning: Call to function 'sprintf' is insecure as it does not provide security checks introduced in the C11 standard. Replace with analogous functions that support length arguments or provides boundary checks such as 'sprintf_s' in case of C11 [clang-analyzer-security.insecureAPI.DeprecatedOrUnsafeBufferHandling] sprintf(buf, "%u", n); ^~~~~~~ arr04.c:7:5: note: Call to function 'sprintf' is insecure as it does not provide security checks introduced in the C11 standard. Replace with analogous functions that support length arguments or provides boundary checks such as 'sprintf_s' in case of C11 sprintf(buf, "%u", n); ^~~~~~~ arr04.c:10:5: warning: Call to function 'strcpy' is insecure as it does not provide bounding of the memory buffer. Replace unbounded copy functions with analogous functions that support length arguments such as 'strlcpy'. CWE-119 [clang-analyzer-security.insecureAPI.strcpy] strcpy(buf, str); ^~~~~~ arr04.c:10:5: note: Call to function 'strcpy' is insecure as it does not provide bounding of the memory buffer. Replace unbounded copy functions with analogous functions that support length arguments such as 'strlcpy'. CWE-119 strcpy(buf, str); ^~~~~~
clang-tidy 只发现了第二处错误,未能找到第一处错误.
cppcheck
1 2 3
arr04.c:10:12: error: Buffer is accessed out of bounds: buf [bufferAccessOutOfBounds] strcpy(buf, str); ^
cppcheck 只发现了第二处错误,未能找到第一处错误.
AddressSanitizer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
stack-buffer-overflow on address 0x7ffc1fa69e48 at pc 0x000000498768 bp 0x7ffc1fa69d20 sp 0x7ffc1fa694d0 WRITE of size 11 at 0x7ffc1fa69e48 thread T0 #0 0x498767 in __interceptor_vsprintf (/tmp/123.out+0x498767) #1 0x498ad6 in sprintf (/tmp/123.out+0x498ad6) #2 0x500bf1 in main arr04.c:7:5 #3 0x7fba9700eb24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16 #4 0x41f12d in _start /usr/src/debug/glibc-2.33/csu/../sysdeps/x86_64/start.S:120
Address 0x7ffc1fa69e48 is located in stack of thread T0 at offset 40 in frame #0 0x500b1f in main arr04.c:4
This frame has 1 object(s): [32, 40) 'buf' (line 6) <== Memory access at offset 40 overflows this variable HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork (longjmp and C++ exceptions *are* supported) SUMMARY: AddressSanitizer: stack-buffer-overflow (/tmp/123.out+0x498767) in __interceptor_vsprintf
mem02.c:5:5: warning: Call to function 'strcpy' is insecure as it does not provide bounding of the memory buffer. Replace unbounded copy functions with analogous functions that support length arguments such as 'strlcpy'. CWE-119 [clang-analyzer-security.insecureAPI.strcpy] strcpy(buf, "hello world"); ^~~~~~ mem02.c:5:5: note: Call to function 'strcpy' is insecure as it does not provide bounding of the memory buffer. Replace unbounded copy functions with analogous functions that support length arguments such as 'strlcpy'. CWE-119 strcpy(buf, "hello world"); ^~~~~~ mem02.c:7:5: warning: Attempt to free released memory [clang-analyzer-unix.Malloc] free(buf); ^~~~~~~~~ mem02.c:4:17: note: Memory is allocated char *buf = malloc(10); ^~~~~~~~~~ mem02.c:6:5: note: Memory is released free(buf); ^~~~~~~~~ mem02.c:7:5: note: Attempt to free released memory free(buf); ^~~~~~~~~ mem02.c:8:5: warning: Call to function 'strcpy' is insecure as it does not provide bounding of the memory buffer. Replace unbounded copy functions with analogous functions that support length arguments such as 'strlcpy'. CWE-119 [clang-analyzer-security.insecureAPI.strcpy] strcpy(buf, "123456"); ^~~~~~ mem02.c:8:5: note: Call to function 'strcpy' is insecure as it does not provide bounding of the memory buffer. Replace unbounded copy functions with analogous functions that support length arguments such as 'strlcpy'. CWE-119 strcpy(buf, "123456"); ^~~~~~
cppcheck
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
mem02.c:5:12: error: Buffer is accessed out of bounds: buf [bufferAccessOutOfBounds] strcpy(buf, "hello world"); ^ mem02.c:4:15: note: Assign buf, buffer with size 10 char *buf = malloc(10); ^ mem02.c:5:12: note: Buffer overrun strcpy(buf, "hello world"); ^ mem02.c:7:5: error: Memory pointed to by 'buf' is freed twice. [doubleFree] free(buf); ^ mem02.c:6:5: note: Memory pointed to by 'buf' is freed twice. free(buf); ^ mem02.c:7:5: note: Memory pointed to by 'buf' is freed twice. free(buf); ^
AddressSanitizer
1 2 3 4 5 6 7 8 9 10 11 12 13 14
AddressSanitizer: heap-buffer-overflow on address 0x60200000001a at pc 0x000000489aef bp 0x7ffef9e30a40 sp 0x7ffef9e301f0 WRITE of size 12 at 0x60200000001a thread T0 #0 0x489aee in __interceptor_strcpy.part.0 asan_interceptors.cpp.o #1 0x500b33 in main mem02.c:5:5 #2 0x7f00689feb24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16 #3 0x41f12d in _start /usr/src/debug/glibc-2.33/csu/../sysdeps/x86_64/start.S:120
0x60200000001a is located 0 bytes to the right of 10-byte region [0x602000000010,0x60200000001a) allocated by thread T0 here: #0 0x4c7d99 in __interceptor_malloc (/tmp/123.out+0x4c7d99) #1 0x500b21 in main mem02.c:4:17 #2 0x7f00689feb24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16
SUMMARY: AddressSanitizer: heap-buffer-overflow asan_interceptors.cpp.o in __interceptor_strcpy.part.0
这次基础的测试中,clang-tidy、cppcheck 均能检测出内存的二次释放,也给出了有关不安全的 api strcpy 的警告,但未能对使用释放后的内存给出提示. valgrind memcheck
Invalid write of size 1 at 0x4844914: strcpy (vg_replace_strmem.c:523) by 0x401173: main (mem02.c:5) Address 0x4a4404a is 0 bytes after a block of size 10 alloc'd at 0x483E7C5: malloc (vg_replace_malloc.c:380) by 0x401161: main (mem02.c:4) Invalid write of size 1 at 0x4844926: strcpy (vg_replace_strmem.c:523) by 0x401173: main (mem02.c:5) Address 0x4a4404b is 1 bytes after a block of size 10 alloc'd at 0x483E7C5: malloc (vg_replace_malloc.c:380) by 0x401161: main (mem02.c:4) Invalid free() / delete / delete[] / realloc() at 0x484118B: free (vg_replace_malloc.c:755) by 0x401185: main (mem02.c:7) Address 0x4a44040 is 0 bytes inside a block of size 10 free'd at 0x484118B: free (vg_replace_malloc.c:755) by 0x40117C: main (mem02.c:6) Block was alloc'd at at 0x483E7C5: malloc (vg_replace_malloc.c:380) by 0x401161: main (mem02.c:4) Invalid write of size 1 at 0x4844914: strcpy (vg_replace_strmem.c:523) by 0x401193: main (mem02.c:8) Address 0x4a44040 is 0 bytes inside a block of size 10 free'd at 0x484118B: free (vg_replace_malloc.c:755) by 0x40117C: main (mem02.c:6) Block was alloc'd at at 0x483E7C5: malloc (vg_replace_malloc.c:380) by 0x401161: main (mem02.c:4) Invalid write of size 1 at 0x4844926: strcpy (vg_replace_strmem.c:523) by 0x401193: main (mem02.c:8) Address 0x4a44046 is 6 bytes inside a block of size 10 free'd at 0x484118B: free (vg_replace_malloc.c:755) by 0x40117C: main (mem02.c:6) Block was alloc'd at at 0x483E7C5: malloc (vg_replace_malloc.c:380) by 0x401161: main (mem02.c:4) HEAP SUMMARY: in use at exit: 0 bytes in 0 blocks total heap usage: 1 allocs, 2 frees, 10 bytes allocated All heap blocks were freed -- no leaks are possible For lists of detected and suppressed errors, rerun with: -s ERROR SUMMARY: 10 errors from 5 contexts (suppressed: 0 from 0)
复杂的多次释放
1 2 3 4 5 6 7 8 9 10 11 12
#include <stdlib.h> #include <string.h> int main() { char *table[5]; for (int i = 0; i < 5; i++) { table[i] = malloc(0x10); strncpy(table[i], "1234567890", 11); } for (int i = 0; i < 10; i++) { free(table[rand() % 5]); } }
clang-tidy
1 2 3 4 5 6
mem07.c:7:9: warning: Call to function 'strncpy' is insecure as it does not provide security checks introduced in the C11 standard. Replace with analogous functions that support length arguments or provides boundary checks such as 'strncpy_s' in case of C11 [clang-analyzer-security.insecureAPI.DeprecatedOrUnsafeBufferHandling] strncpy(table[i], "1234567890", 11); ^~~~~~~ mem07.c:7:9: note: Call to function 'strncpy' is insecure as it does not provide security checks introduced in the C11 standard. Replace with analogous functions that support length arguments or provides boundary checks such as 'strncpy_s' in case of C11 strncpy(table[i], "1234567890", 11); ^~~~~~~
很遗憾,clang-tidy 只是告诉开发者更换更安全的 api 来防止溢出,对本程序中的多次释放内存的问题视而不见. cppcheck 也未能给出有价值的信息.
AddressSanitizer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
attempting double-free on 0x602000000070 in thread T0: #0 0x4c7af9 in free (/tmp/123.out+0x4c7af9) #1 0x500d39 in main mem07.c:10:9 #2 0x7f8e0d928b24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16 #3 0x41f14d in _start /usr/src/debug/glibc-2.33/csu/../sysdeps/x86_64/start.S:120
0x602000000070 is located 0 bytes inside of 16-byte region [0x602000000070,0x602000000080) freed by thread T0 here: #0 0x4c7af9 in free (/tmp/123.out+0x4c7af9) #1 0x500d39 in main mem07.c:10:9 #2 0x7f8e0d928b24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16
previously allocated by thread T0 here: #0 0x4c7db9 in __interceptor_malloc (/tmp/123.out+0x4c7db9) #1 0x500c3d in main mem07.c:6:20 #2 0x7f8e0d928b24 in __libc_start_main /usr/src/debug/glibc-2.33/csu/../csu/libc-start.c:332:16
SUMMARY: AddressSanitizer: double-free (/tmp/123.out+0x4c7af9) in free
valgrind memcheck
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Invalid free() / delete / delete[] / realloc() at 0x484118B: free (vg_replace_malloc.c:755) by 0x4011EB: main (mem07.c:10) Address 0x4a44130 is 0 bytes inside a block of size 16 free'd at 0x484118B: free (vg_replace_malloc.c:755) by 0x4011EB: main (mem07.c:10) Block was alloc'd at at 0x483E7C5: malloc (vg_replace_malloc.c:380) by 0x401189: main (mem07.c:6) HEAP SUMMARY: in use at exit: 0 bytes in 0 blocks total heap usage: 5 allocs, 10 frees, 80 bytes allocated All heap blocks were freed -- no leaks are possible For lists of detected and suppressed errors, rerun with: -s ERROR SUMMARY: 5 errors from 1 contexts (suppressed: 0 from 0)
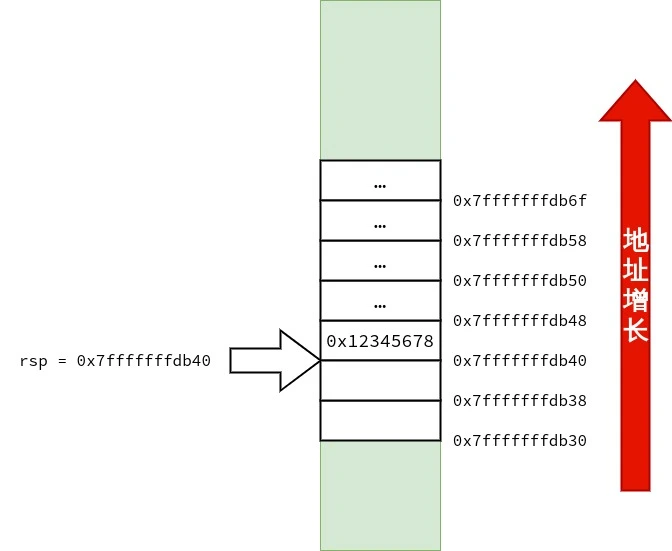
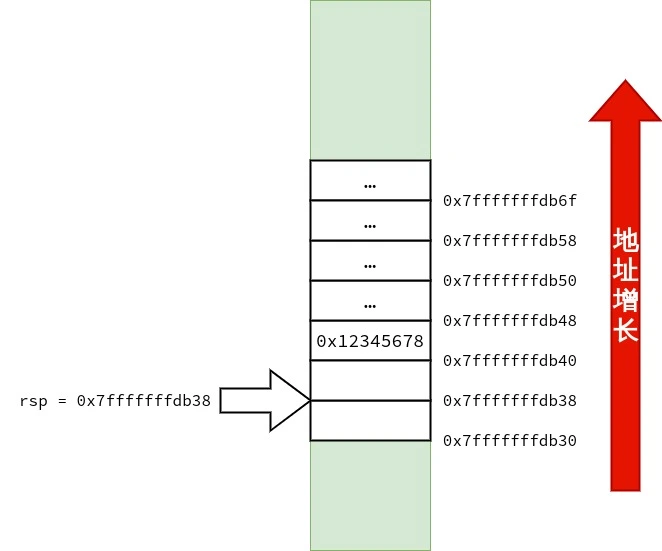
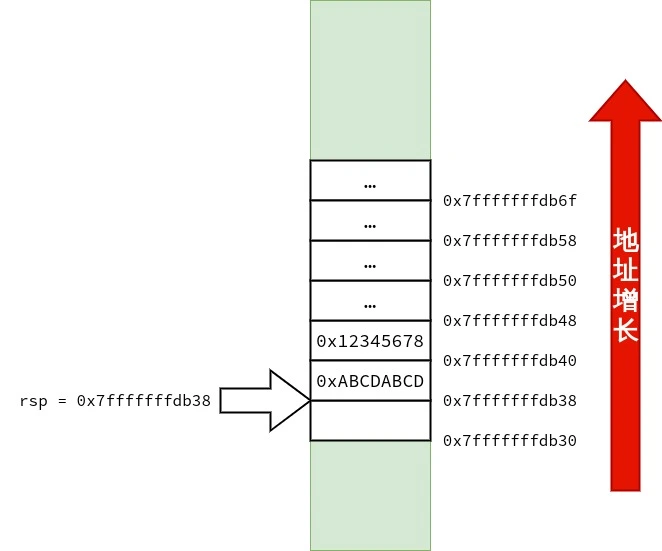
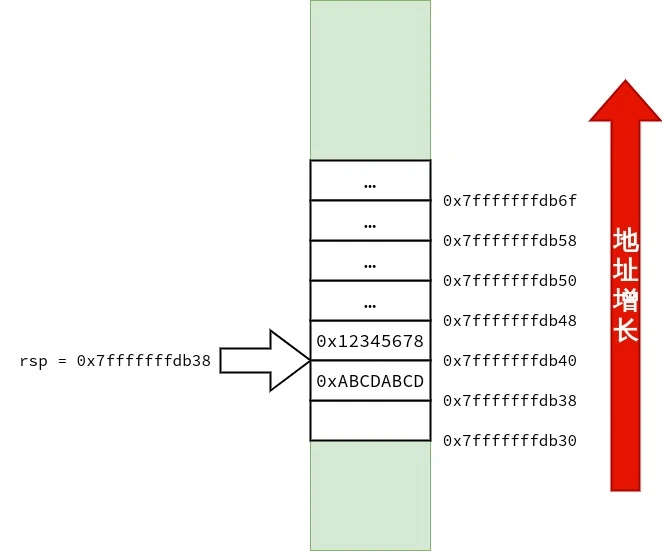
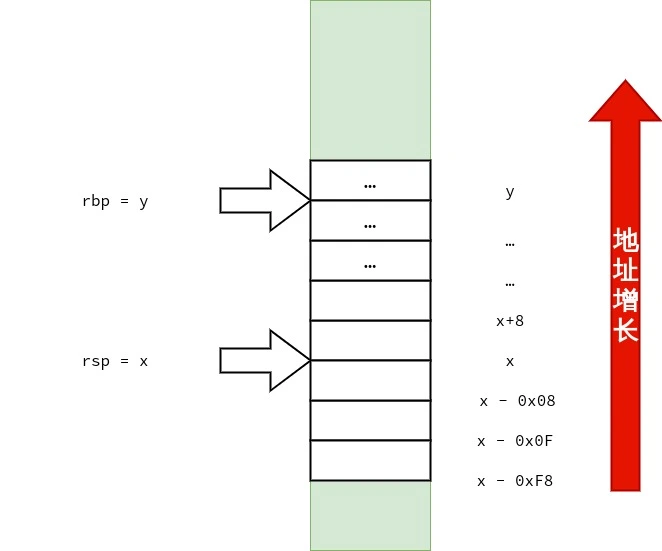
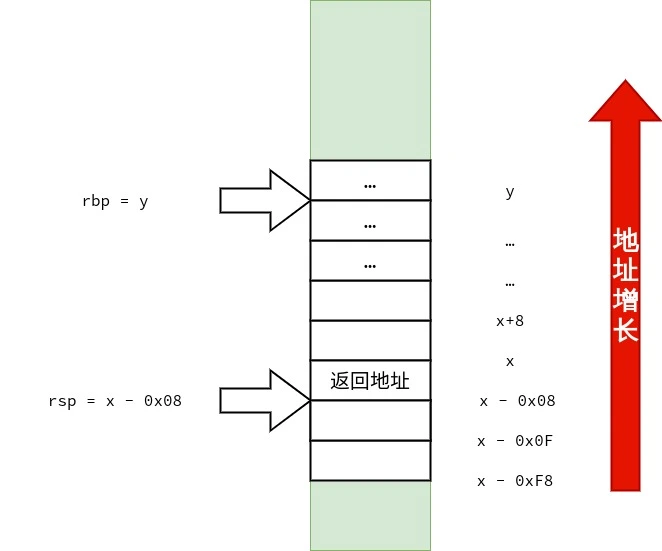
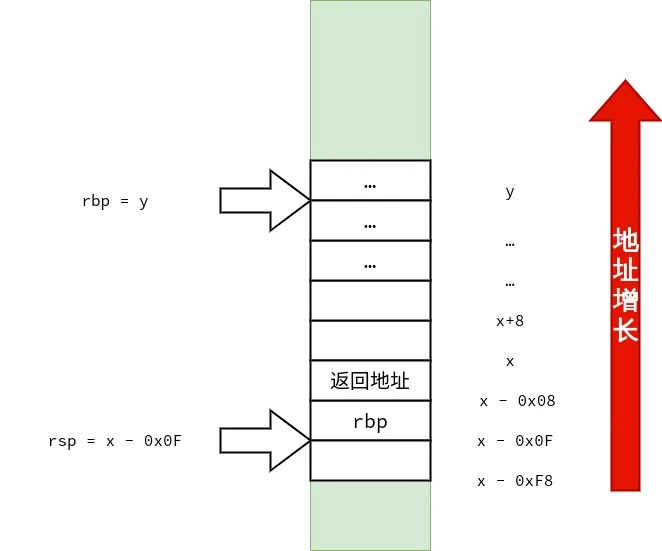
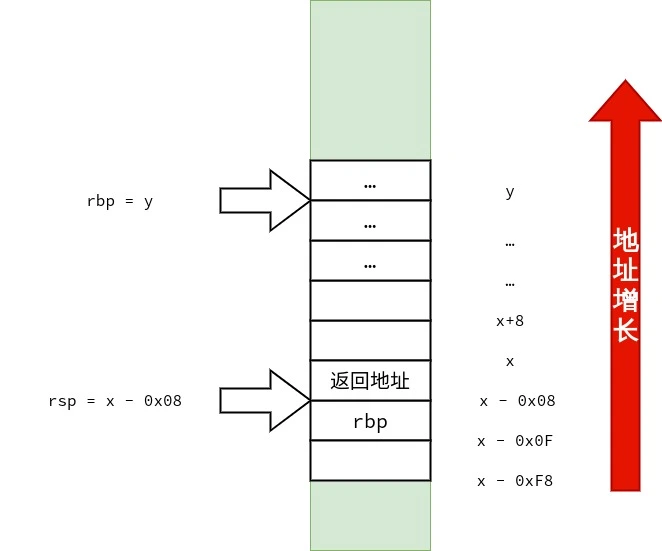
/* call3.c */ voidfunc1() { } intfunc3(int a, int b, int c, int d, int e, int f, int g, int h, int i, int j) { func1(); return a * 1 + b * 2 + c * 3 + d * 4 + e * 5 + f * 6 + g * 7 + h * 8 + i * 9 + j * 10; } intmain() { func3(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); }
首先,笔者要声明的是:调用约定与设备的 ABI(application binary interface)有关,而 ABI 依赖「硬件特性」与「操作系统」.在 x86-64 上也不只有一种调用约定.
Microsoft x64 calling convention
这张表展示了 Microsoft x64 calling convention 的部分内容,笔者展示这张表的目的不在于向读者介绍 Microsoft x64 calling convention 的具体内容,仅仅是为了说明调用约定不止一种.当遇到与笔者接下来介绍的 System V AMD64 ABI 不同的调用约定时,也不要对此感到惊奇和诧异.
众所周知,C++ 的非静态成员函数有一个隐式的参数就是 *this 指向成员函数所在的类的类型的指针. 例如: 在考虑 C++ 与汇编代码的关系时,可以将本例中 sum 的理解为:
1 2 3 4
intsum(class test *this) { returnthis->a + this->b; }
简而言之,C++ 非静态非虚成员函数含有一个隐式的 this 指针参数,作为第一个参数传递.
这与上文所说的一致.
「第一个小于等于 8 bytes 的整形参数在 System V AMD64 ABI」通过 rdi 传递
好,现在尝试增多 C++ 非静态非虚成员函数 的参数数量.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#include<cstdio> classtest { int a, b;
public: test() = default; intsum2(int u, int v, int w, int x, int y, int z) { return a + b + u + v + w + x + y + z; } }; intmain() { test t; int s = t.sum2(1, 2, 3, 4, 5, 6); printf("%d\n", s); }
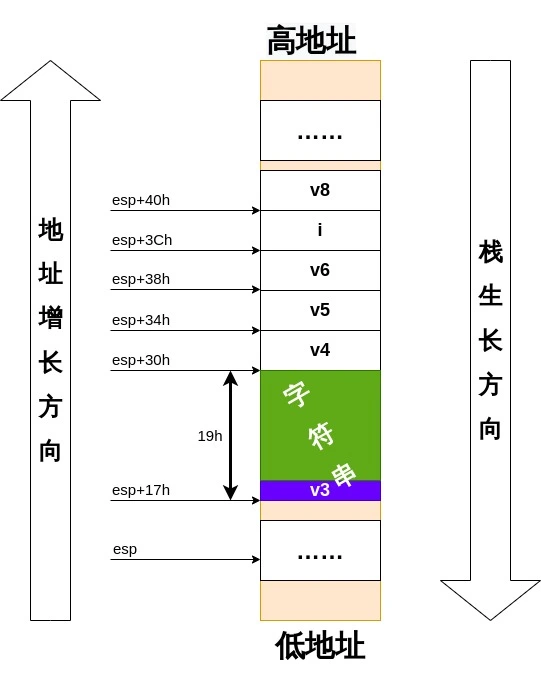
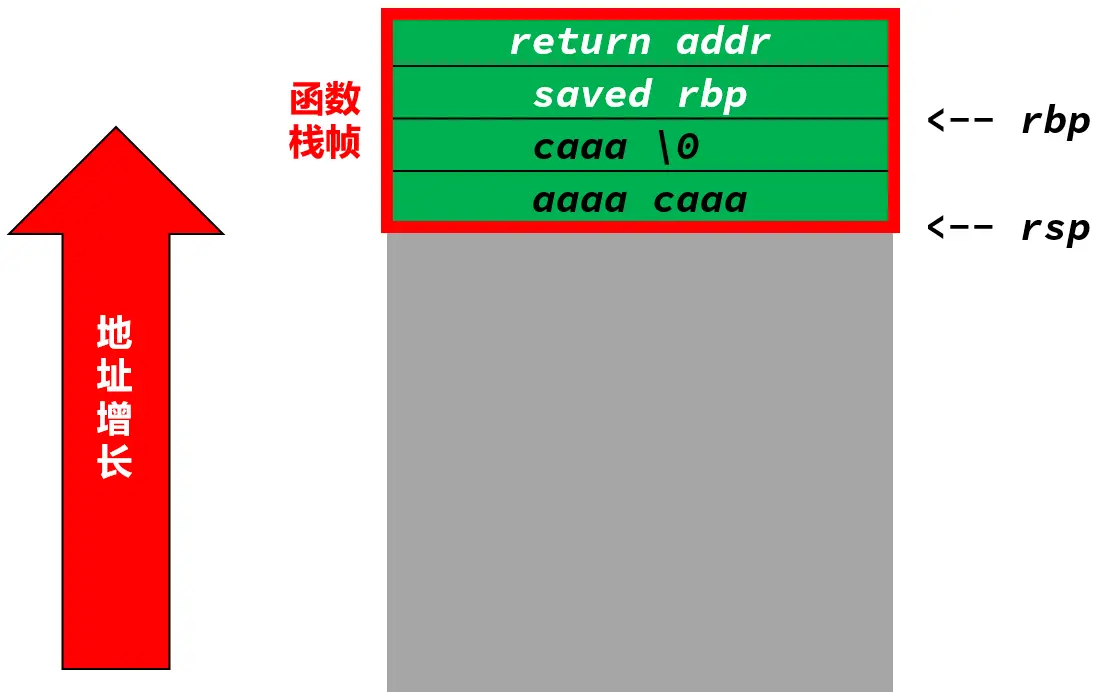
![Signal[2]](/img/ProcessOfSignalHandlering.webp)
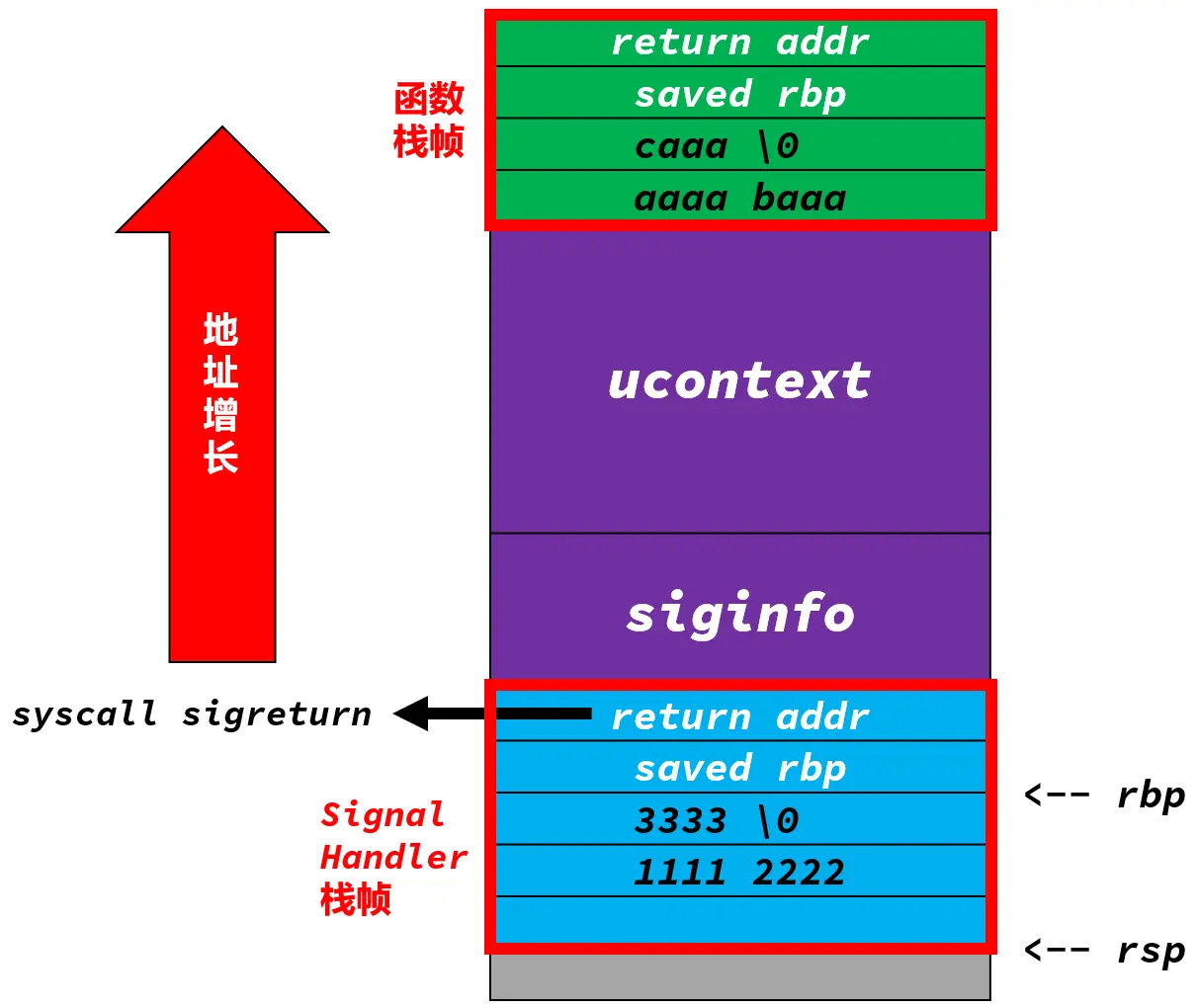
![Signal Frame[1]](/img/signal_frame.webp)