Speed up DNSDist with AF_XDP
Chinese readers can read the Chinese version of this article.
中文读者可阅读本文的中文版本。
Preface
DNSDist is an excellent DNS load balancer, and AF_XDP is an emerging high-performance Linux asynchronous IO interface that benefits from eBPF.
It is a great honor for Y7n05h to participate in the AF_XDP transformation of DNSDist as a contributor.
It’s an honor to have Y7n05h as a contributor to improve DNSDist with AF_XDP.
The changes to the UDP part of DNSDist have long since come to an end. This performance-improving modification requires profiling data to validate.
So, let’s start the fun performance analysis.
Test environment information
Laptop
OS: ArchLinux
Kernel Version: 5.19.1-arch2-1
CPU: AMD Ryzen 7 4800H with Radeon Graphics
MEM: DDR4 64G
NIC: Intel Corporation Wi-Fi 6 AX200 (rev 1a)
DNSPerf Version: 2.9.0
GCC Version: 12.1.1
Libxdp Version:1.2.5
PC1
OS: ArchLinux
Kernel Version: 5.19.1-arch2-1
CPU: Intel(R) Core(TM) i5-8500 CPU @ 3.00GHz
MEM: DDR4 8G
NIC: Intel Corporation Wi-Fi 6 AX200 (rev 1a)
PC2
OS: Ubuntu
Kernel Version: 5.15.0-46-generic
CPU: 12th Gen Intel(R) Core(TM) i7-12700KF
MEM: DDR4 64G
NIC: Broadcom Inc. and subsidiaries BCM4360 802.11ac Wireless Network Adapter (rev 03)
Thanks to @yegetables for lending PC2 to Y7n05h.
Source Code:
DNSDist With AF_XDP(AF_XDP verion): https://github.com/Y7n05h/pdns/commit/d42e356a48a433a9f4efae9c3dd648101a37abdf
DNSDist Without AF_XDP(Normal version): https://github.com/Y7n05h/pdns/commit/f5e76c2a6932ec4360d38219fb515d26d538b40d
In this test, Y7n05h uses Laptop to generate the requests for testing, PC1 to run the DNSDist instance to be tested, and PC2 to run the SmartDNS service.
Laptop, PC1 and PC2 are all connected to the gateway (192.168.30.1) using WIFI, and Laptop, PC1 and PC2 access each other via WIFI. Unfortunately, the network used in this test environment was still used by numerous other devices during the test, so Y7n05h cannot exclude experimental errors caused by fluctuations in the network environment.
The test tool uses DNSPerf. The test resolves A records for 12018 different domains, only once for each domain in each test.
For the tests, SmartDNS was used as the DNS server. There is no particular reason to use SmartDNS, except that Y7n05h is familiar with it and it is easy to build and deploy SmartDNS on Ubuntu.
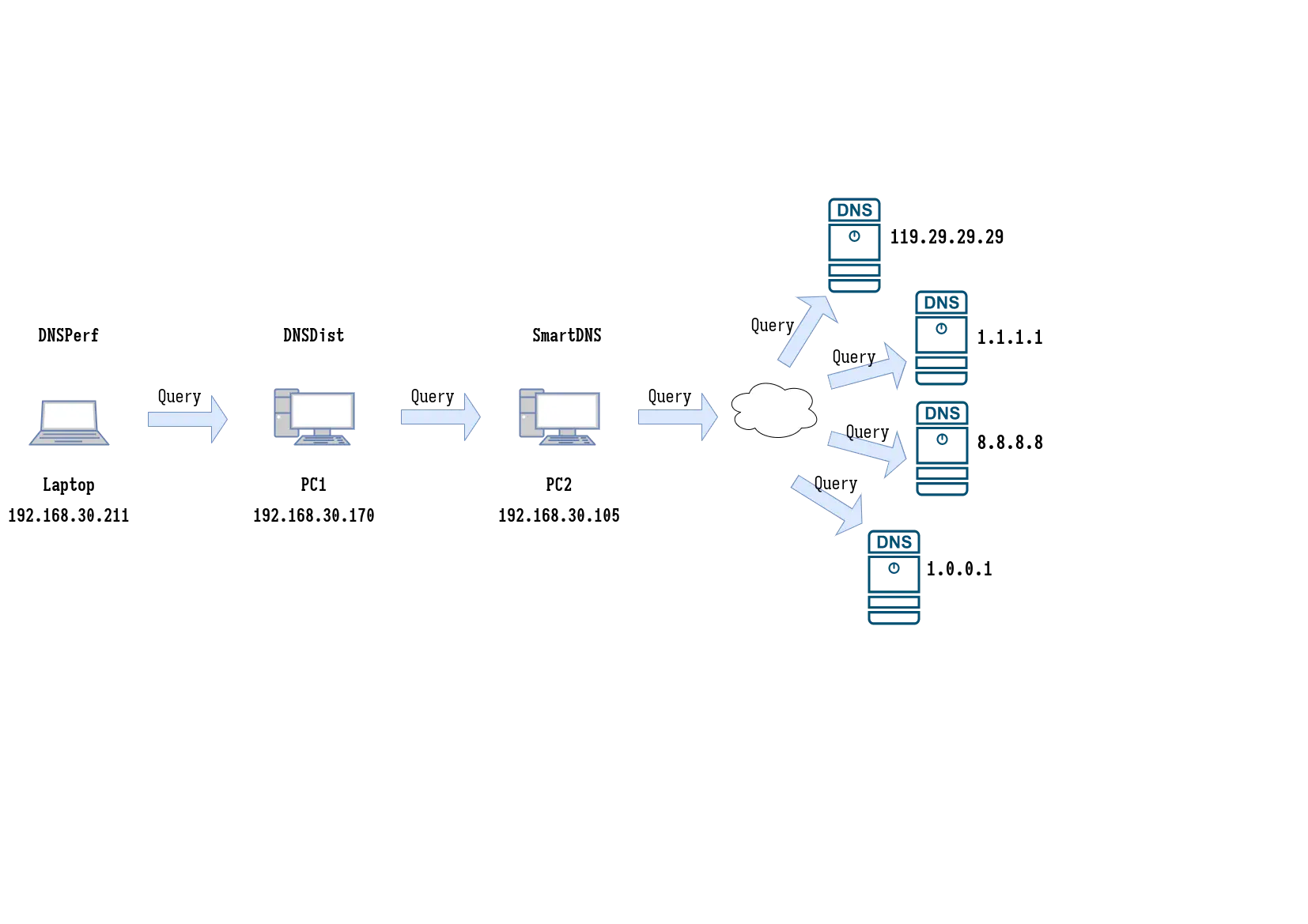
During the test, Y7n05h used Laptop to send DNS query requests to PC1 running DNSDist. SmartDNS then concurrently sends the DNS requests to the 4 DNS servers 1.1.1.1, 1.0.0.1, 8.8.8.8, 119.29.29.29 (if necessary) and replies to DNSDist with the first response received.
In this test, Y7n05h sent a lot of DNS query requests to the above 4 public DNS servers frequently due to testing needs, Y7n05h expresses sincere thanks to Cloudflare, Google, DNSPod for providing these public DNS services. (Although Y7n05h performed a large number of DNS queries during the test, these queries are cached by DNSDist, SmartDNS, and not every query sends a request to the above servers. (Therefore Y7n05h feels this is acceptable, which is fundamentally different from DDoS.) Also, in order to eliminate as much interference as possible from the DNS service’s cache for this test, Y7n05h has used DNSPerf to repeatedly send resolution requests to SmartDNS for all domains used in the test before the start of this test.
In the current network environment, Y7n05h’s subjective guess is that DNS query requests are still dominated by A records and AAAA records. Since Y7n05h’s environment does not have good IPv6 support, the resolution of A records was used as a performance indicator in this test. Since Y7n05h cannot verify the correctness of the DNS resolution results, we do not consider correctness as a metric in this performance analysis.
It should also be noted that the DNSDist configuration used in this test has been simplified for testing purposes and may differ significantly from the DNSDist configuration in the production environment. Therefore, this test by Y7n05h does not fully reflect the performance of AF_XDP’s optimization of DNSDist in a production environment.
As we all know, the DNS protocol uses recursive resolution, and the response time of requests is greatly affected by whether the query domain hits the DNS server’s cache or not.
In summary, this test by Y7n05h may be biased and may be inaccurate. The following is only the opinion of Y7n05h.
Performance Tests
The uniq.txt contains and only contains 12018 non-repeating domains.
In this article, the horizontal axis of all lines is the number of runs, and the number of DNSPerf runs is incremented by 1 for each DNSPerf run, the result of multiple DNSPerf executions for the same DNSDist process instance on the same curve. The points on the same curve are listed in chronological order from left to right. Any two DNSPerf’s do not overlap.
To simplify the exposition of this paper, Y7n05h hereby agrees with the reader that
- The version of DNSDist that uses AF_XDP is omitted as “AF_XDP version”.
- DNSDist version without AF_XDP is omitted as “Normal version”.
Test 1
The following command was used in this test to run DNSPerf:
1 | dnsperf -s 192.168.30.170 -p 5300 -d uniq.txt |
In test 1, Y7n05h ran the AF_XDP version first, then the Normal version, and finally the AF_XDP version again.
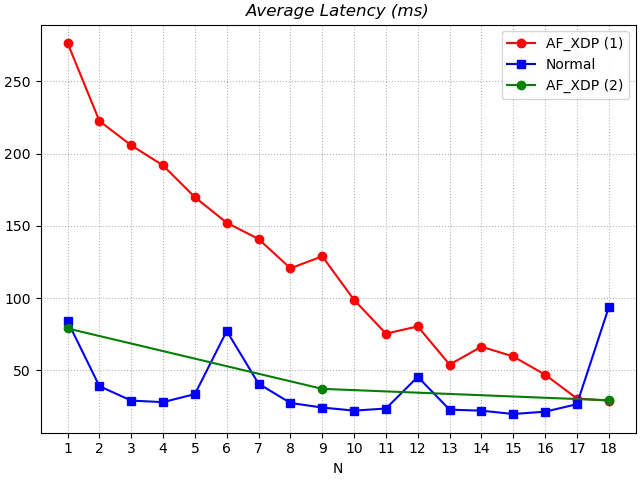
Looking at the average latency first, there is a decreasing trend in the average latency regardless of the fold. The decreasing average latency is generally due to the fact that after multiple DNSPerf executions, SmartDNS and the downstream servers have increased their hit rate for the domain name caches involved in the DNSPerf in this test. This is evidenced by the fact that the average latency of “re-running AF_XDP version” after “running Normal version” is significantly lower than the previous test results. Based on the data available at this time, it is not possible to determine the impact of AF_XDP on average latency.
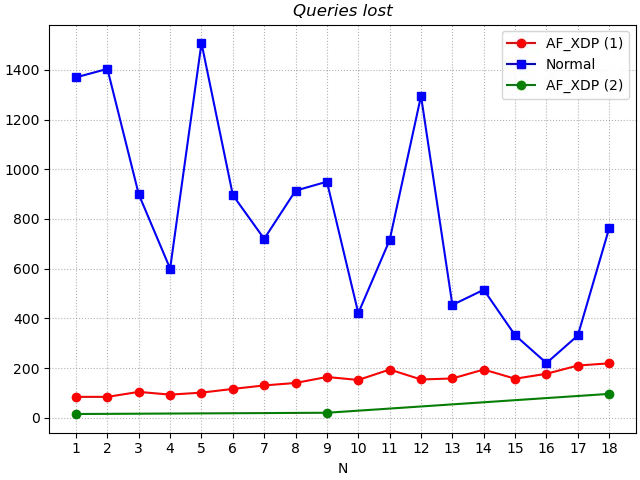
For the metric of query loss, the AF_XDP version is significantly lower than the Normal version. The number of lost queries with the AF_XDP version tends to increase slowly with the number of tests.
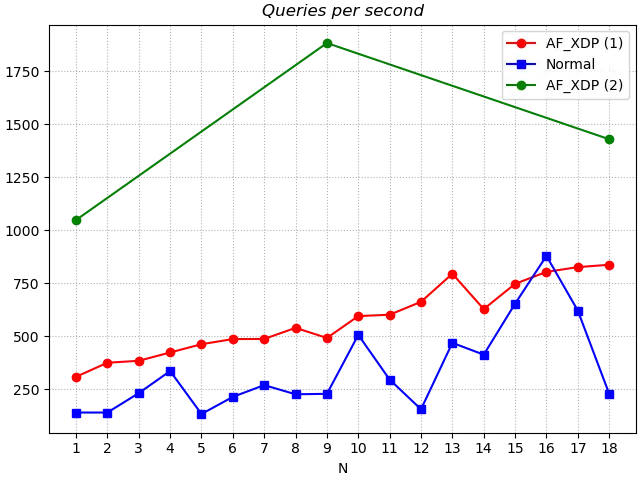
For the average number of queries per second, or throughput, using the AF_XDP version is significantly better than the Normal version. Considering that the fetch time of the data in the blue curve is between the green and red curves, the effect of caching on the AF_XDP version is that it enhances the green curve and degrades the red curve. This is a strong enough comparison for the non-AF_XDP version of DNSDist with the blue curve to show the throughput advantage of AF_XDP.
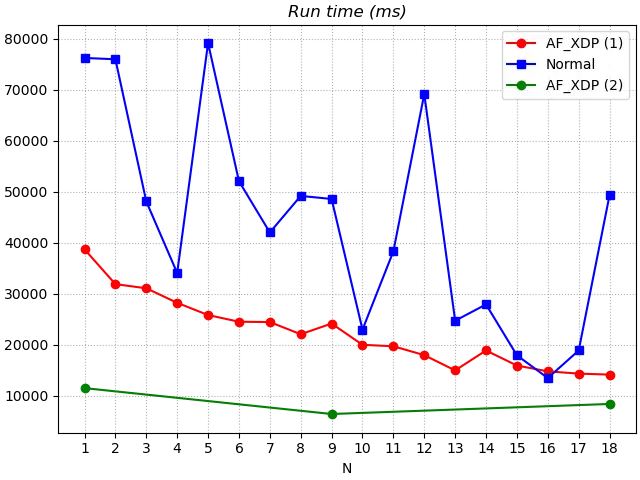
The runtime is the time consumed for a complete execution of DNSPerf. The conclusion here is also that the AF_XDP version outperforms the Normal version. The conclusions here are similar to those from the throughput analysis, and Y7n05h does not repeat them.
Even considering the caching impact on DNS in queries such as DNSDist, SmartDNS, etc. results in DNSPerf speeding up in the time dimension one by one. What can be clearly concluded at this point is that AF_XDP significantly improves DNSDist’s throughput in the current scenario. The impact on query latency may still require further testing.
Test 2
The following command was used in this test to run DNSPerf:
1 | dnsperf -s 192.168.30.170 -p 5300 -d uniq.txt -c 500 -T 16 |
In Test 2, the concurrency of the test was increased by adding command line arguments. Test 2 ran the Normal version first and the AF_XDP version second.
Note: Test 2 was not run consecutively with Test 1, which may have affected the DNS cache.
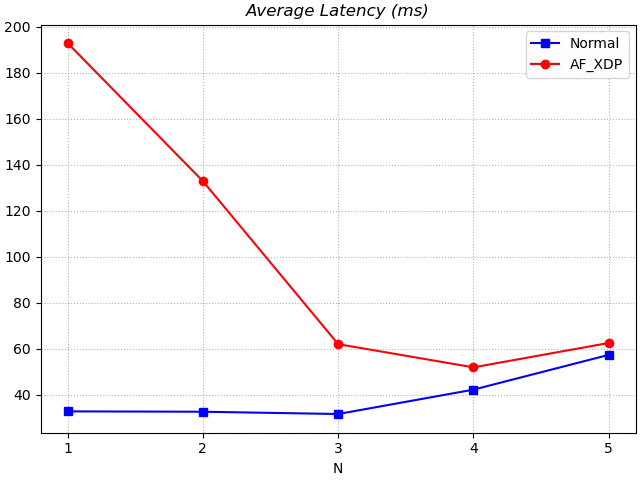
The average latency of the AF_XDP version is still decreasing and is not significantly different from the Normal version in the last two tests. y7n05h I personally guess that if we increase the number of tests, the average latency of the AF_XDP version may be lower than the Normal version as the cache command increases. The average significant latency of the AF_XDP version was higher than the Normal version in the first 3 tests, perhaps because the cache in DNSDist was cleared by stopping the Normal version and running the AF_XDP version. the effect of AF_XDP on the average latency still needs further testing.
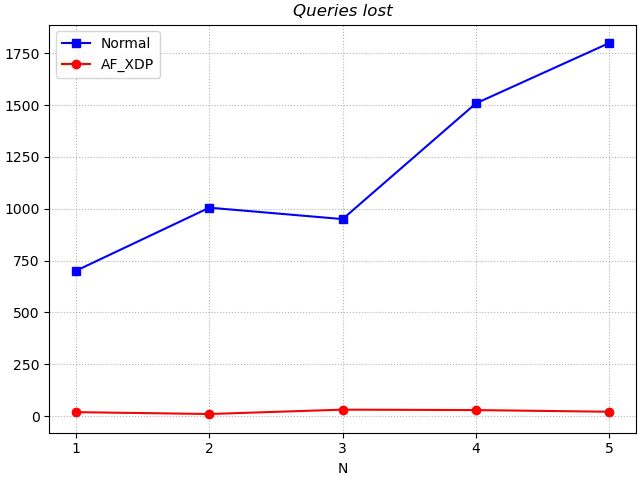
Comparing the query misses for the Normal and AF_XDP versions, they remain similar to those in Test 1. There is also no significant change in the number of queries lost compared to Test 1.
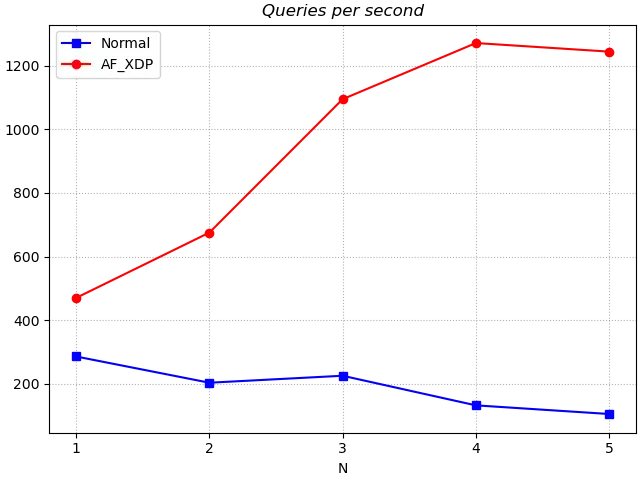
In terms of throughput, the gap between the AF_XDP version and the Normal version increases further for more concurrent query requests, and tends to increase with the number of tests.
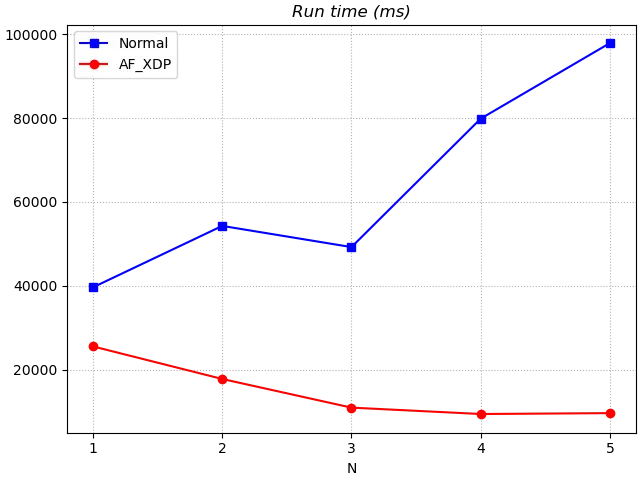
The AF_XDP version is significantly less time consuming than the Normal version for one DNSPerf execution. This is similar to what was found in Test 1.
Summary
AF_XDP significantly improves DNSDist throughput, but risks increasing the average latency per request (which needs to be further verified).
In terms of throughput alone, it is conservatively estimated that AF_XDP can more than double the throughput of DNSDist.
From the tests here, it appears that AF_XDP is a technique that has the potential to significantly improve the throughput of UDP-based web services.