x86_64 函数调用 本文将讨论 x86_64 平台的函数调用过程,简要介绍部分常见的调用约定.阅读本文需要读者对 x86_64 汇编语言有一些基本的了解.
本文只讨论「长度不大于 64 bit 的整数类型」与「指针类型」作为函数参数、返回值时传递的方式,不涉及「长度大于 64 bit 的整数类型参数」与结构体、浮点数等类型的传递方式.
本文代码为了展示函数调用与返回过程中的汇编语言实现,引入了大量无意义、冗余的代码,本文代码不能作为学习编程语言中写法的推荐或参考.
前置知识 栈 相信很多人都遇到过因函数的递归次数过多,导致程序运行时出现栈溢出的问题.这个溢出的「栈」是本文要关注的重点,函数调用的过程和它密不可分.
info INFO
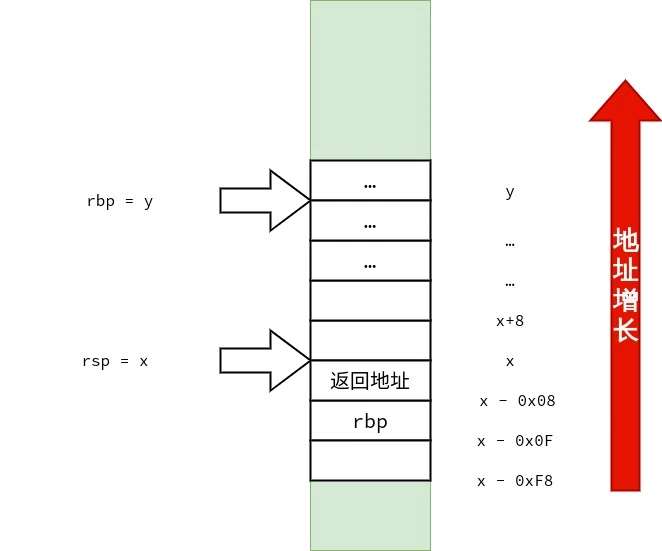
PUSHPUSH 操作类似数据结构中的「堆栈」 .PUSH 指令总是
递减 rsp将 PUSH 的值存储在 rsp 递减后指向的位置PUSH 过程意在强调:在 PUSH 操作中, rsp 指向的是最后一个数据的位置,而不是指向栈上待写入数据的位置.rsp 总是指向有效的数据. POPPOP 操作与 PUSH 操作相对应.POP 指令总是:
将栈顶的值取出 递增 rsptip TIP rsp 指向的值.
LEAVELEAVE 操作是等价于
1 2 mov %rbp , %rsp pop %rbp
也就是:
通过执行 mov %rbp , %rsp(rsp = rbp),恢复 rsp 至执行 CALL 后的位置. 通过执行 pop %rbp,恢复 rbp 至原来的栈底. 无返回值与参数的「函数调用与返回过程」 本小节将说明函数无参数、无返回值的函数调用与返回的过程.请读者们将关注点集中理解在函数调用的流程上,不必过多的关注具体的细节.
首先,尝试写出简单的函数调用的示例.
1 2 3 4 5 6 7 8 9 void func1 () { int v = 0 ; } int main (void ) { func1(); }
查看该程序的反汇编代码:clang 生成并使用 objdump 反编译获得,笔者已删去其中的次要部分(删节部分并未全部标注).(后同)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <func1>: push %rbp mov %rsp,%rbp sub $0x10,%rsp ;此处有删节 leave ret <main>: ;此处有删节 call 1147 <func1> mov $0x0,%eax pop %rbp ret
首先请关注由 main() 到 func1() 的调用过程.
在 main(),执行 call 1147 <func1> 就完成了对 func1 的调用.call 将 main() 中下一条语句的地址(也就是「mov $0x0,%eax」这句的地址)压入栈中并修改 rip 的值为 func1() 的地址. 在 func1(),通过将 rbp 压栈的方式,保存 rbp. tip TIP rbp 里面的值的部分.call 1147 <func1> 时 rbp 的值是多少.rbp 指向栈的某一个位置,而且 rbp < rsp 即可.
通过执行 mov %rsp,%rbp(rbp = rsp),原来的栈底(rbp 指向的位置)成为了新的栈顶(rsp 指向的位置) 此时调用函数 func1() 的过程结束.现在关注如何从 func1() 返回至 main().
函数返回时,使用 LEAVE 恢复了先前保存栈底. 使用 ret 根据 rsp 指向的位置从栈中弹出 返回位置,并通过修改 rip的值为 返回地址 完成了函数的返回. 有返回值和参数的「函数调用与返回过程」上 无返回值与参数的「函数调用与返回过程」可以看作本节要讨论的 有返回值和参数的「函数调用与返回过程」的一种简化情况.
和上一节一样,研究一个简单的函数示例对理解该过程有帮助.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void func1 () { } int func2 (int a, long b, char *c) { *c = a * b; func1(); return a * b; } int main () { char value; int rc = func2(1 , 2 , &value); }
反汇编后得到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 <func1>: push %rbp mov %rsp,%rbp pop %rbp ret <func2>: push %rbp mov %rsp,%rbp sub $0x20,%rsp mov %edi,-0x4(%rbp) mov %rsi,-0x10(%rbp) mov %rdx,-0x18(%rbp) movslq -0x4(%rbp),%rax imul -0x10(%rbp),%rax mov -0x18(%rbp),%rcx mov %al,(%rcx) call 1140 <func1> movslq -0x4(%rbp),%rcx imul -0x10(%rbp),%rcx mov %ecx,%eax add $0x20,%rsp pop %rbp ret <main>: push %rbp mov %rsp,%rbp sub $0x10,%rsp mov %fs:0x28,%rax mov %rax,-0x8(%rbp) mov $0x1,%edi mov $0x2,%esi lea -0x9(%rbp),%rdx call 1150 <func2> mov %eax,-0x10(%rbp) mov %fs:0x28,%rcx mov -0x8(%rbp),%rdx cmp %rdx,%rcx jne 11d9 <main+0x49> xor %eax,%eax add $0x10,%rsp pop %rbp ret
可以清晰的看到,在执行 call 1140 <func2> 之前 main() 进行了如下操作:
1 2 3 mov $0x1,%edi mov $0x2,%esi lea -0x9(%rbp),%rdx
事实上,这三条语句意在进行参数的传递.在进行函数调用时,主调函数将参数存储在寄存器中,在被调函数中直接使用,通过这样的方式传递参数.
观察函数调用的实参 1, 2, &value,可以看到:
1 使用 rdi 的低 32 位,也就是 edi 来传递.2 使用 rsi 的低 32 位,也就是 esi 来传递.&value 使用 rdx 进行传递.值得注意的是:即使 &value 的类型是指针,与 整型变量 看似不同,但在传递方式上并无差异.
这是 func2() 的尾部代码片段:
1 2 3 4 5 imul -0x10(%rbp),%rcx mov %ecx,%eax add $0x20,%rsp pop %rbp ret
可以看到乘法产生的结果通过
mov %ecx,%eax 放在了
rax 的低 32 位(
eax)中.返回后,在
main() 有:
1 2 call 1150 <func2> mov %eax,-0x10(%rbp)
请看,此处 eax 中仍是 func2() 中计算的 a * b 的值,但在 main() 却进行了读取.这不就是从 被调函数 中传送给主调函数的值吗?是的,rax 寄存器常常被用来传递返回值.
讨论完了返回值与参数,此时再来看看 func2() 的调用流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <func2>: push %rbp mov %rsp,%rbp sub $0x20,%rsp mov %edi,-0x4(%rbp) mov %rsi,-0x10(%rbp) mov %rdx,-0x18(%rbp) movslq -0x4(%rbp),%rax imul -0x10(%rbp),%rax mov -0x18(%rbp),%rcx mov %al,(%rcx) call 1140 <func1> movslq -0x4(%rbp),%rcx imul -0x10(%rbp),%rcx mov %ecx,%eax add $0x20,%rsp pop %rbp ret
相信不难注意到:sub $0x20,%rsp.前文提及过,栈是由高地址向低地址的方向增长的.rsp 减少 0x20 意味着栈增长 0x20.那么栈为什么需要增长呢?因为需要在栈上为 func2() 的局部变量或临时的变量等分配空间.与 sub $0x20,%rsp 对应的操作是 add $0x20,%rsp 在函数返回前需要增加 rsp 以释放栈上的空间.其余步骤与 无返回值与参数的「函数调用与返回过程」 所述并无实质差异,此处不再赘述.
有返回值和参数的「函数调用与返回过程」下 前面的小节中,描述了函数参数较少的情况下参数传递的方式.本节则将关注较多的参数将为函数的调用带来什么变化.
1 2 3 4 5 6 7 8 9 10 11 12 13 void func1 () { } int func3 (int a, int b, int c, int d, int e, int f, int g, int h, int i, int j) { func1(); return a * 1 + b * 2 + c * 3 + d * 4 + e * 5 + f * 6 + g * 7 + h * 8 + i * 9 + j * 10 ; } int main () { func3(1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ); }
反汇编得到了较长的汇编代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 <func1>: push %rbp mov %rsp,%rbp pop %rbp ret <func3>: push %rbp mov %rsp,%rbp push %rbx sub $0x28,%rsp mov 0x28(%rbp),%eax mov 0x20(%rbp),%r10d mov 0x18(%rbp),%r11d mov 0x10(%rbp),%ebx mov %edi,-0xc(%rbp) mov %esi,-0x10(%rbp) mov %edx,-0x14(%rbp) mov %ecx,-0x18(%rbp) mov %r8d,-0x1c(%rbp) mov %r9d,-0x20(%rbp) mov %eax,-0x24(%rbp) mov %r10d,-0x28(%rbp) mov %r11d,-0x2c(%rbp) mov %ebx,-0x30(%rbp) call 1120 <func1> mov -0xc(%rbp),%eax shl $0x0,%eax mov -0x10(%rbp),%ecx shl $0x1,%ecx add %ecx,%eax imul $0x3,-0x14(%rbp),%ecx add %ecx,%eax mov -0x18(%rbp),%ecx shl $0x2,%ecx add %ecx,%eax imul $0x5,-0x1c(%rbp),%ecx add %ecx,%eax imul $0x6,-0x20(%rbp),%ecx add %ecx,%eax imul $0x7,0x10(%rbp),%ecx add %ecx,%eax mov 0x18(%rbp),%ecx shl $0x3,%ecx add %ecx,%eax imul $0x9,0x20(%rbp),%ecx add %ecx,%eax imul $0xa,0x28(%rbp),%ecx add %ecx,%eax add $0x28,%rsp pop %rbx pop %rbp ret <main>: push %rbp mov %rsp,%rbp sub $0x30,%rsp mov $0x1,%edi mov $0x2,%esi mov $0x3,%edx mov $0x4,%ecx mov $0x5,%r8d mov $0x6,%r9d movl $0x7,(%rsp) movl $0x8,0x8(%rsp) movl $0x9,0x10(%rsp) movl $0xa,0x18(%rsp) call 1130 <func3> xor %ecx,%ecx mov %eax,-0x4(%rbp) mov %ecx,%eax add $0x30,%rsp pop %rbp ret
笔者首先关注的是 main() 的这个部分:
1 2 3 4 5 6 7 8 9 10 11 mov $0x1,%edi mov $0x2,%esi mov $0x3,%edx mov $0x4,%ecx mov $0x5,%r8d mov $0x6,%r9d movl $0x7,(%rsp) movl $0x8,0x8(%rsp) movl $0x9,0x10(%rsp) movl $0xa,0x18(%rsp) call 1130 <func3>
可以发现.在进行参数的传递时,第 1 个参数(从 1 开始计数)至第 6 个参数分别采用 rdi、rsi、rdx、rcx、r8、r9 这 6 个寄存器对应的低 32 位部分.而剩余的 4 个参数采取了压栈的方式进行传递.
x86-64 调用约定 首先,笔者要声明的是:调用约定与设备的 ABI(application binary interface)有关,而 ABI 依赖「硬件特性」与「操作系统」.在 x86-64 上也不只有一种调用约定.
Microsoft x64 calling convention 这张表展示了 Microsoft x64 calling convention 的部分内容,笔者展示这张表的目的不在于向读者介绍 Microsoft x64 calling convention 的具体内容,仅仅是为了说明调用约定不止一种.当遇到与笔者接下来介绍的 System V AMD64 ABI 不同的调用约定时,也不要对此感到惊奇和诧异.
Parameter type fifth and higher fourth third second leftmost floating-point stack XMM3 XMM2 XMM1 XMM0 integer stack R9 R8 RDX RCX Aggregates (8, 16, 32, or 64 bits) and __m64 stack R9 R8 RDX RCX Other aggregates, as pointers stack R9 R8 RDX RCX __m128, as a pointer stack R9 R8 RDX RCX
[3]
System V AMD64 ABI 本节中将介绍 System V AMD64 ABI 的部分特性.
函数的前六个参数(每个参数均小于等于 8 byte 且不为浮点型变量)将由左至右依次存放在 rdi、rsi、rdx、rcx、r8、r9 的相应位置,更多的参数将由右向左依次入栈,借助栈完成参数的传递.返回值将保存在 rax 中.
请看代码:
1 2 3 4 5 int func4 (int a, unsigned b, long c, unsigned long d, long long e, unsigned long long f) ;int main () { func4(1 , 2U , 3L , 4UL , 5LL , 6ULL ); }
通过编译器与反汇编工具可以得到这段代码的汇编语言描述.
1 2 3 4 5 6 7 8 9 10 11 12 13 <main>: push %rbp mov %rsp,%rbp mov $0x6,%r9d mov $0x5,%r8d mov $0x4,%ecx mov $0x3,%edx mov $0x2,%esi mov $0x1,%edi call 29 <main+0x29> mov $0x0,%eax pop %rbp ret
可以看到常量(更准确的叫法是「立即数」)0x1 被存放在 edi、0x2 被存放在 esi、0x3 被存放在 edx、0x4 被存放在 ecx、0x5 被存放在 r8d、0x6 被存放在 r9d.rdi 吗?怎么放在 edi 里了?(后面的几个参数也会有雷同的疑惑)」edi 在 x86_64 上是 rdi 的低 32 位;类似的,esi 在 x86_64 上是 rsi 的低 32 位;edx 在 x86_64 上是 rdx 的低 32 位;ecx 在 x86_64 上是 rcx 的低 32 位,r8d 在 x86_64 上是 r8 的低 32 位;r9d 在 x86_64 上是 r9 的低 32 位.
值的注意的还有一点:在 x86_64 平台上,例如: mov $0x1,%edi 等源操作数为 double word 的 mov 指令中,目的寄存器的高 32 位会被置为 0.这也使得可以使用将 零扩展 与 复制 一步完成.
info INFO
本文将不会给予进一步说明的是:
XMM0 到 XMM7 用来放置浮点型变量对于系统调用,R10 用来替代 RCX [4] 回看上文中给出的示例,将会发现文中示例无不符合了 System V AMD64 ABI 的要求.
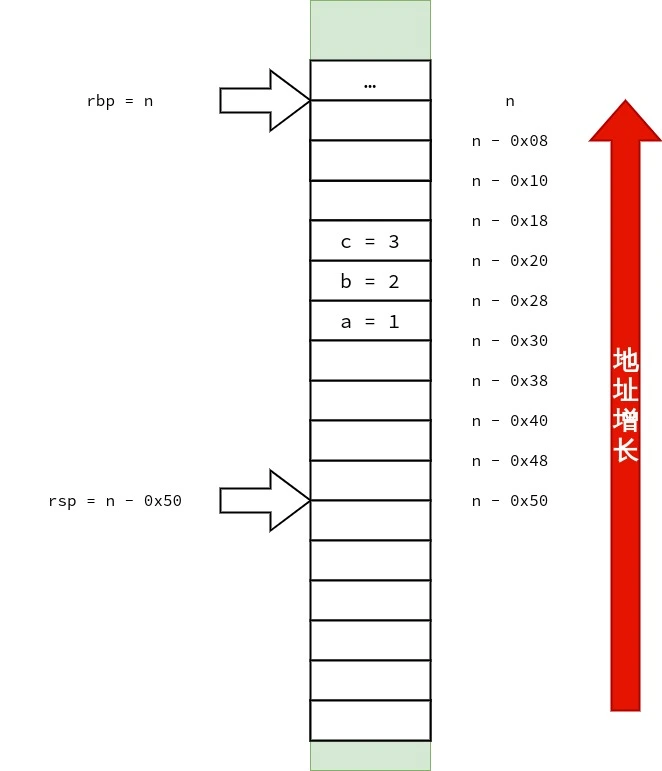
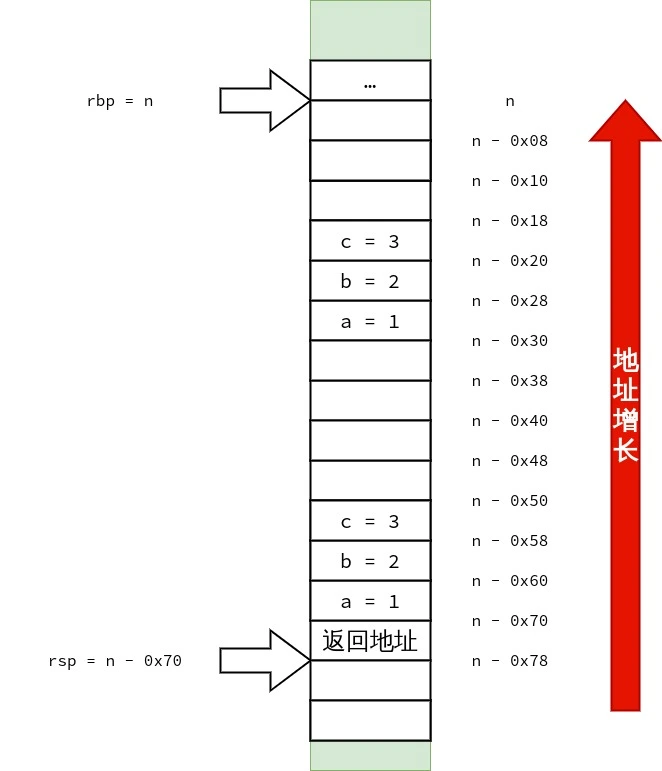
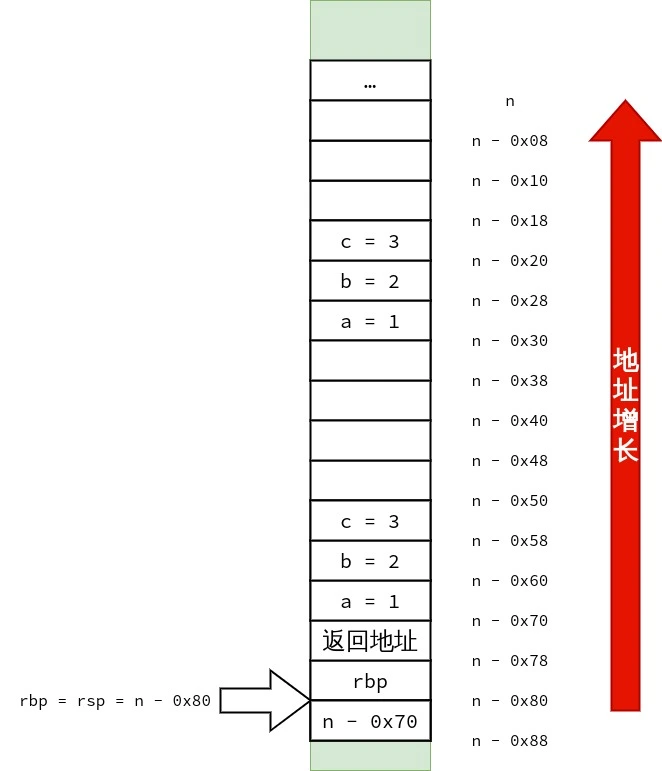
结构体的按值传递 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 struct test_small { int a; char ch[4 ]; }; struct test_small func1 (struct test_small arg) { arg.a = 0 ; arg.ch[0 ] = 3 ; return arg; } struct test_big { long a, b, c; }; struct test_big func2 (struct test_big arg) { arg.a = arg.b + arg.c; return arg; } int main () { struct test_small s ; func1(s); struct test_big b ; b.a = 1 ; b.b = 2 ; b.c = 3 ; func2(b); }
可以看到源码中定义了两个结构体.其中 struct test_small 大小为 8 bytes,struct test_big 大小为 24 bytes.
通过反汇编可以得到:
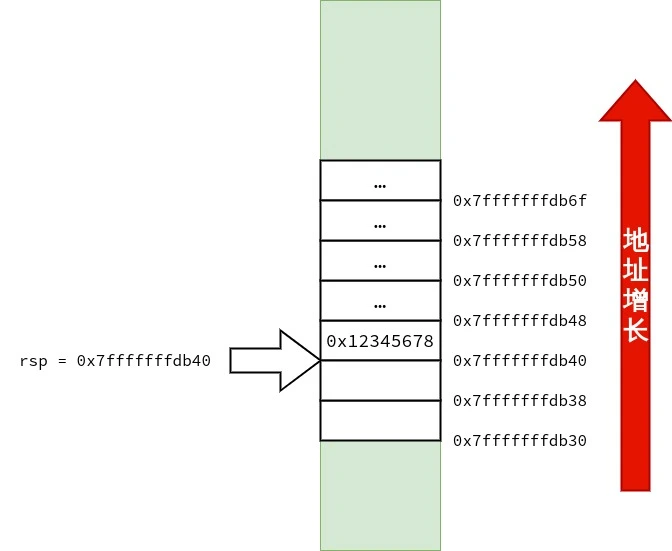
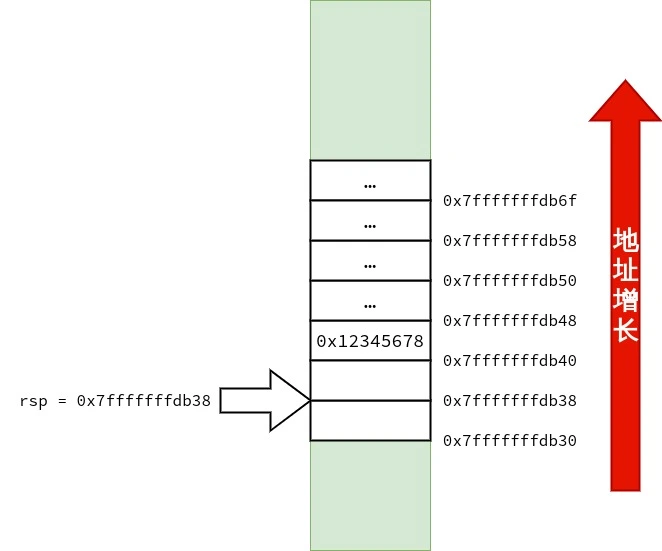
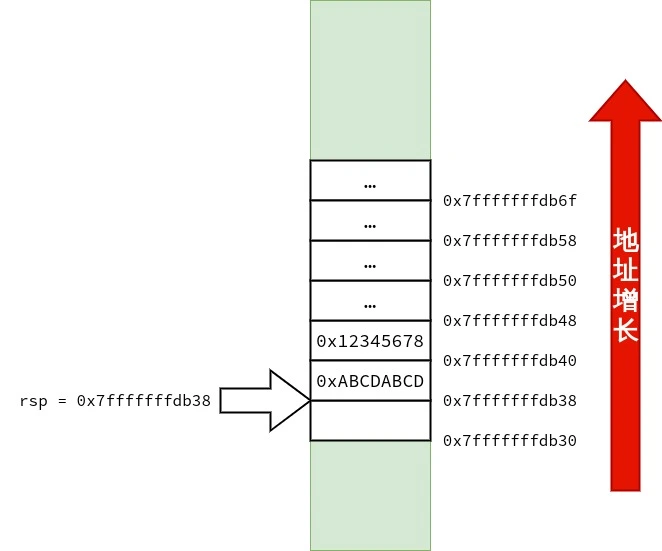
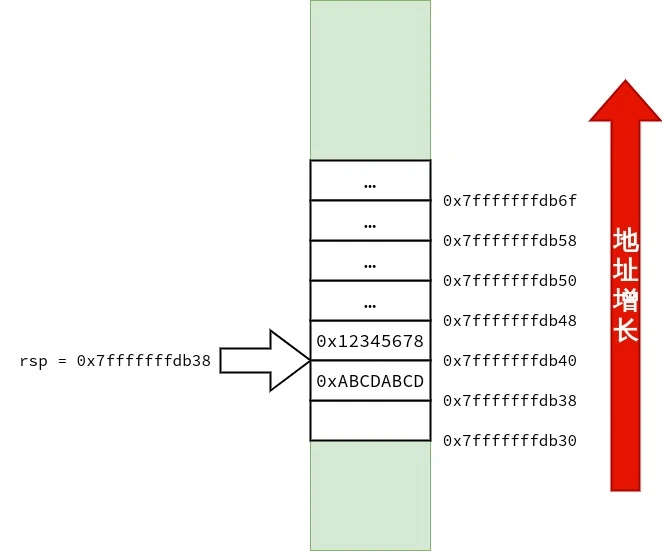
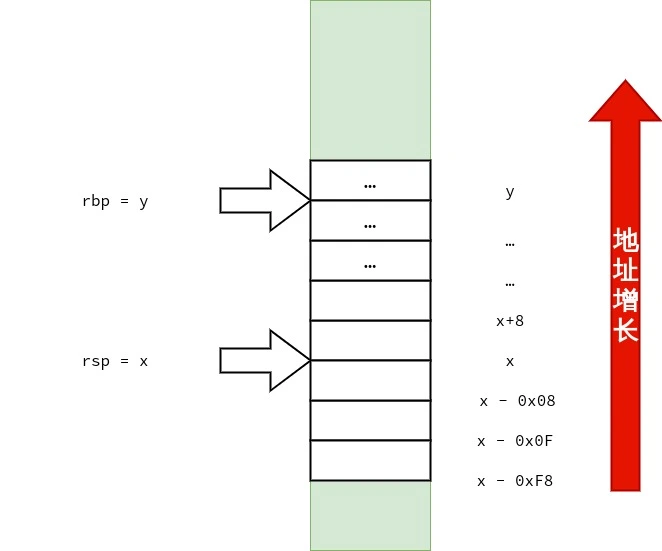
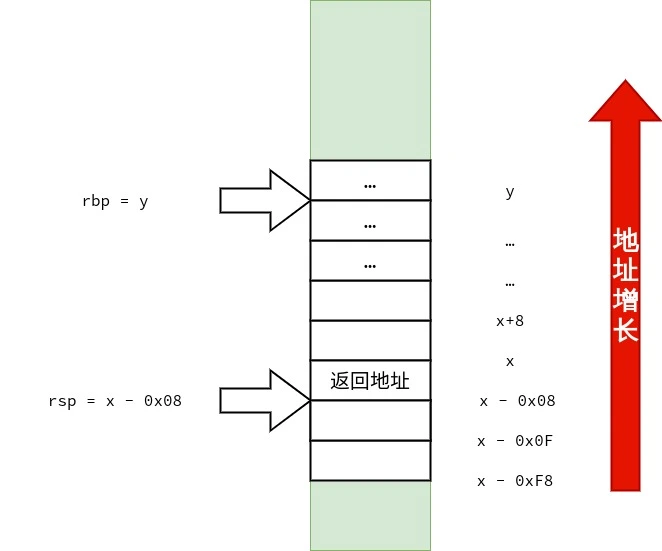
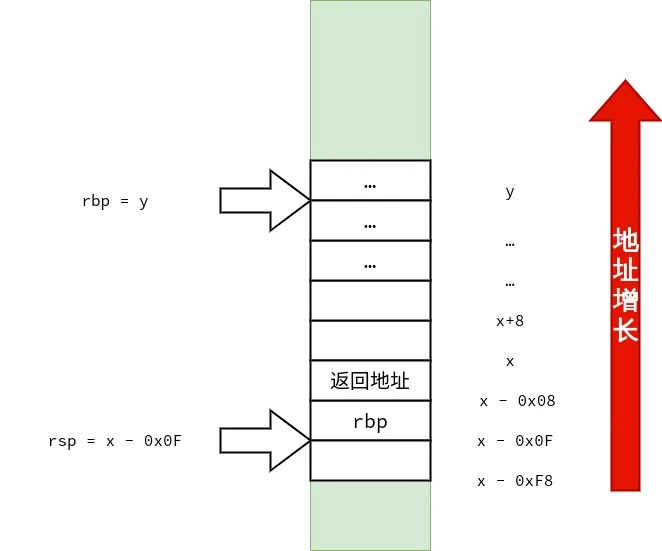
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 <func1>: push %rbp mov %rsp,%rbp mov %rdi,-0x8(%rbp) # 将 rdi 中的 strcut test_small arg 复制到 rbp - 0x8 movl $0x0,-0x8(%rbp) # arg.a = 0 ; movb $0x3,-0x4(%rbp) # arg.ch[0] = 3 ; mov -0x8(%rbp),%rax # 将 arg 复制在 rax 中返回 pop %rbp ret <func2>: push %rbp mov %rsp,%rbp mov %rdi,-0x8(%rbp) # rdi 里存放的是 arg 的地址,把 arg 的地址复制到 rbp - 0x8 mov 0x18(%rbp),%rdx # 把 在 main() 中复制到栈上的 b.c 复制到 rdx mov 0x20(%rbp),%rax # 把 在 main() 中复制到栈上的 b.b 复制到 rax add %rdx,%rax # arg.b + arg.c mov %rax,0x10(%rbp) # arg.a = arg.b + arg.c mov -0x8(%rbp),%rcx # arg 的地址被放在了 rcx 里 mov 0x10(%rbp),%rax mov 0x18(%rbp),%rdx mov %rax,(%rcx) # 本行开始是为返回 arg 作准备 arg.a = arg.a mov %rdx,0x8(%rcx) # arg.b = arg.b mov 0x20(%rbp),%rax # 把 rbp + 0x20 指向的值复制到 rax mov %rax,0x10(%rcx) # arg.c = arg.c mov -0x8(%rbp),%rax # 把 arg 的地址放在 rax 里返回 pop %rbp ret <main>: push %rbp mov %rsp,%rbp # rbp = rsp sub $0x50,%rsp # rsp -= 0x50 所以 rsp == rbp - 0x50 mov %fs:0x28,%rax mov %rax,-0x8(%rbp) xor %eax,%eax mov -0x10(%rbp),%rax # 将 rbp - 0x10 处的 Quad Word 复制到 rax.rbp - 0x10 存放的是 s. mov %rax,%rdi # 将 rax 里的 s 复制到 rdi.作为 struct test_small arg 实参传递给 func1(). call 1139 <func1> # 调用 func1() movq $0x1,-0x30(%rbp) # b.a = 1 ; movq $0x2,-0x28(%rbp) # b.b = 2 ; movq $0x3,-0x20(%rbp) # b.c = 3 ; lea -0x50(%rbp),%rax # 当前栈顶的地址为 rbp - 0x50,将栈顶的地址复制到 rax push -0x20(%rbp) # 将 b.c 压入栈 push -0x28(%rbp) # 将 b.b 压入栈 push -0x30(%rbp) # 将 b.a 压入栈,这三次压栈完成了对 结构体 struct test_big b 的复制,且 struct test_big b 的副本的地址已存放在了 rax mov %rax,%rdi # 将 struct test_big b 的副本的地址复制给 rdi. call 1152 <func2> # 调用 func2() add $0x18,%rsp mov $0x0,%eax mov -0x8(%rbp),%rdx sub %fs:0x28,%rdx je 11f7 <main+0x6d> call 1030 <__stack_chk_fail@plt> leave ret
可以看到大小为 8 bytes 的 struct test_small 存储在 rdi 中完成了传递.而大小为 24 bytes 的struct test_big 则无法存放仅仅能容纳 8 bytes 的 rdi 中,自然没法使用 rdi 进行传递.使用栈完成对 struct test_big 等大于 8 bytes 的结构体(当然也不仅仅只是结构体,联合体、int128_t 等数据也使用类似的方式传递)进行传递成为了仅有的办法.
本段代码中,func2 的逻辑较为复杂,可能需要读者将 main() 与 func2() 相互参考才能明白其中的逻辑.
笔者也画了三张图用来表示 struct test_big 的传递过程,供读者参考.
需要提醒一下的是:结构体的大小并不是结构体的各个成员的大小的代数和.结构体的大小还需要考虑内存对齐的因素.在判断结构体的按值传递方式时,内存对齐将是一个不容忽略的因素.
通过这次的分析,可以发现,大结构体(大于 8 bytes)的按值传递的效率较低.当对程序的运行效率有较高的要求时,应当首先考虑传址而不是传值.
C++ 与参数传递 在 x86_64 Linux 平台上,C++ 的程序的普通函数调用过程与上文中所述并无差异.
将上文代码使用 g++ 编译后重新反汇编得到的代码为:
1 2 3 4 5 int func4 (int a, unsigned b, long c, unsigned long d, long long e, unsigned long long f) ;int main () { func4(1 , 2U , 3L , 4UL , 5LL , 6ULL ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 <main>: push %rbp mov %rsp,%rbp mov $0x6,%r9d mov $0x5,%r8d mov $0x4,%ecx mov $0x3,%edx mov $0x2,%esi mov $0x1,%edi call 29 <main+0x29> mov $0x0,%eax pop %rbp ret
但类的非静态成员函数的调用与上文有较多不同.在不同中,又可分为两类:
非虚成员函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <cstdio> class test { int a, b; public : test () = default ; int sum () { return a + b; } }; int main () test t; int s = t.sum (); printf ("%d\n" , s); }
C++ 语言通过 g++ 生成的程序反汇编得到的代码可能没有 C 语言通过 gcc 生成的程序反汇编的得到的代码那么简单易懂.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <main>: push %rbp mov %rsp,%rbp sub $0x20,%rsp mov %fs:0x28,%rax mov %rax,-0x8(%rbp) xor %eax,%eax lea -0x10(%rbp),%rax # -0x10(%rbp) 是个局部变量,本指令将局部变量的地址存储在了 rax mov %rax,%rdi # 将 rax 拷贝至 rdi call 11a0 <_ZN4test3sumEv> # 调用 sum() 函数 mov %eax,-0x14(%rbp) mov -0x14(%rbp),%eax mov %eax,%esi lea 0xe89(%rip),%rdi mov $0x0,%eax call 1030 <printf@plt> mov $0x0,%eax mov -0x8(%rbp),%rdx sub %fs:0x28,%rdx je 119e <main+0x55> call 1040 <__stack_chk_fail@plt> leave ret <_ZN4test3sumEv>: push %rbp mov %rsp,%rbp mov %rdi,-0x8(%rbp) # 把 rdi 中存放的地址拷贝至局部变量 mov -0x8(%rbp),%rax # 将局部变量中存储的地址拷贝至 rax mov (%rax),%edx # 将 rax 指向的 一个 double word 拷贝至 edx mov -0x8(%rbp),%rax # 再次将局部变量中存储的地址拷贝至 rax mov 0x4(%rax),%eax # 将 (rax + 0x4) 的一个 double word 拷贝至 eax add %edx,%eax # 将 edx 加在 eax 上 pop %rbp ret
众所周知,C++ 的非静态成员函数有一个隐式的参数就是 *this 指向成员函数所在的类的类型的指针.sum 的理解为:
1 2 3 4 int sum (class test *this ) return this ->a + this ->b; }
简而言之,C++ 非静态非虚成员函数含有一个隐式的 this 指针参数,作为第一个参数传递.
这与上文所说的一致.
「第一个小于等于 8 bytes 的整形参数在 System V AMD64 ABI」通过 rdi 传递
好,现在尝试增多 C++ 非静态非虚成员函数 的参数数量.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <cstdio> class test { int a, b; public : test () = default ; int sum2 (int u, int v, int w, int x, int y, int z) { return a + b + u + v + w + x + y + z; } }; int main () test t; int s = t.sum2 (1 , 2 , 3 , 4 , 5 , 6 ); printf ("%d\n" , s); }
反汇编得到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 <main>: push %rbp mov %rsp,%rbp sub $0x20,%rsp mov %fs:0x28,%rax mov %rax,-0x8(%rbp) xor %eax,%eax lea -0x10(%rbp),%rax # -0x10(%rbp) 是个局部变量,本指令将局部变量的地址存储在了 rax sub $0x8,%rsp push $0x6 # 注意 这个参数使用了 栈 进行传递 mov $0x5,%r9d # 参数传递 mov $0x4,%r8d # 参数传递 mov $0x3,%ecx # 参数传递 mov $0x2,%edx # 参数传递 mov $0x1,%esi # 参数传递 mov %rax,%rdi # 将 rax 里保存的指针 拷贝至 rdi call 11c6 <_ZN4test4sum2Eiiiiii> # 调用 sum2() 函数 add $0x10,%rsp mov %eax,-0x14(%rbp) mov -0x14(%rbp),%eax mov %eax,%esi lea 0xe64(%rip),%rdi mov $0x0,%eax call 1030 <printf@plt> mov $0x0,%eax mov -0x8(%rbp),%rdx sub %fs:0x28,%rdx je 11c3 <main+0x7a> call 1040 <__stack_chk_fail@plt> leave ret <_ZN4test4sum2Eiiiiii>: push %rbp mov %rsp,%rbp mov %rdi,-0x8(%rbp) # 在栈上保存 rdi,rdi mov %esi,-0xc(%rbp) # 在栈上保存 esi mov %edx,-0x10(%rbp) # 在栈上保存 edx mov %ecx,-0x14(%rbp) # 在栈上保存 ecx mov %r8d,-0x18(%rbp) # 在栈上保存 r8d mov %r9d,-0x1c(%rbp) # 在栈上保存 r8d mov -0x8(%rbp),%rax # rdi 里保存的指针 复制到 rax mov (%rax),%edx # rdi 里保存的指针 指向的 double word 复制到 edx mov -0x8(%rbp),%rax # rdi 里保存的指针 复制到 rax mov 0x4(%rax),%eax # rdi 里保存的指针+0x4 的 double word 复制到 eax add %eax,%edx # eax 加到 edx mov -0xc(%rbp),%eax # -0xc(%rbp) 里是之前 esi 里的值,也就是 形参 int u 的值 add %eax,%edx # eax 加到 edx mov -0x10(%rbp),%eax # -0x10(%rbp) 里是之前 edx 里的值,也就是 形参 int v 的值 add %eax,%edx # eax 加到 edx mov -0x14(%rbp),%eax # -0x14(%rbp) 里是之前 ecx 里的值,也就是 形参 int w 的值 add %eax,%edx # eax 加到 edx mov -0x18(%rbp),%eax # -0x18(%rbp) 里是之前 r8d 里的值,也就是 形参 int x 的值 add %eax,%edx # eax 加到 edx mov -0x1c(%rbp),%eax # -0x1c(%rbp) 里是之前 r9d 里的值,也就是 形参 int y 的值 add %eax,%edx # eax 加到 edx mov 0x10(%rbp),%eax # 0x10(%rbp) 之前被 push 在了栈上,也就是 形参 int z 的值 add %edx,%eax # eax 加到 edx pop %rbp ret
可以看到:算上隐式的 this 指针,函数 sum2() 共有 7 个参数.参数 1-6 仍然依次采用 rdi、rsi、rdx、rcx、r8、r9 进行传递.第 7 个参数 int z 也正常的使用了栈进行传递.
总结一下,C++ 非静态非虚函数成员的调用过程与 C 语言函数的唯一差别在于需要把 *this 理解为一个参数.
虚成员函数 在给出本节的示例之前,笔者认为有必要再次强调下面的代码只是为了演示虚成员函数的调用过程.如果有人在实际的程序设计的情景中仿照笔者给出的这些示例,那么请允许笔者借用 Scott Meyers 的一句话:
把他们隔离起来直到他们保证不再这样做为止
(笔者在Effective C++ 或是 More Effective C++ 中看到过这句话,但找不到具体出处了,这句只是根据自己的回忆写出的).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <cstdio> class test1 { protected : int a; int b; public : test1 (int A, int B) : a (A), b (B) {} virtual void info () { printf ("max=%d\n" , a > b ? a : b); } }; class test2 : public test1{ public : test2 (int x, int y) : test1 (x, y) {} void info () override { printf ("min=%d\n" , a < b ? a : b); } }; int main () test1 t1 (1 , 2 ) ; test2 t2 (3 , 4 ) ; test1 *pr1 = &t1; pr1->info (); test2 *pr2 = &t2; pr2->info (); }
编译后反汇编得到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 <main>: push %rbp mov %rsp,%rbp sub $0x40,%rsp mov %fs:0x28,%rax mov %rax,-0x8(%rbp) xor %eax,%eax lea -0x30(%rbp),%rax # 把 rbp - 0x30 mov $0x2,%edx # 参数 mov $0x1,%esi # 参数 mov %rax,%rdi # 参数 this 指针 call 11de <_ZN5test1C1Eii> # 构造 t1 lea -0x20(%rbp),%rax mov $0x4,%edx # 参数 mov $0x3,%esi # 参数 mov %rax,%rdi # 参数 this 指针 call 1256 <_ZN5test2C1Eii> # 构造 t2 lea -0x30(%rbp),%rax # t1 的地址存放在 rax 里 mov %rax,-0x40(%rbp) # t1 的地址从 rax 里复制到 rbp - 0x40.rbp - 0x40 存储的是 pr1 mov -0x40(%rbp),%rax # 把 pr1 复制到 rax mov (%rax),%rax # 把 pr1 指向的 Quad Word 复制到 rax mov (%rax),%rdx # 把 pr1 指向的 Quad Word 指向的 Quad Word 复制到 rdx mov -0x40(%rbp),%rax # 把 pr1 复制到 rax mov %rax,%rdi # 传递参数,把 this 指针从 rax 复制到 rdi.pr2 的值就是 this 指针的实参. call *%rdx # 调用 rdx 指向的函数指针 lea -0x20(%rbp),%rax # t2 的地址存放在 rax 里 mov %rax,-0x38(%rbp) # t2 的地址从 rax 里复制到 rbp - 0x38.rbp - 0x38 存储的是 pr2 mov -0x38(%rbp),%rax # 把 pr2 复制到 rax mov (%rax),%rax # 把 pr2 指向的 Quad Word 复制到 rax mov (%rax),%rdx # 把 pr2 指向的 Quad Word 指向的 Quad Word 复制到 rdx mov -0x38(%rbp),%rax# 把 pr2 复制到 rax mov %rax,%rdi # 传递参数,把 this 指针从 rax 复制到 rdi.pr2 的值就是 this 指针的实参. call *%rdx # 调用 rdx 指向的函数指针 mov $0x0,%eax mov -0x8(%rbp),%rcx sub %fs:0x28,%rcx je 11db <main+0x92> call 1040 <__stack_chk_fail@plt> leave ret <_ZN5test1C1Eii>: # test1 构造函数 push %rbp mov %rsp,%rbp mov %rdi,-0x8(%rbp) mov %esi,-0xc(%rbp) mov %edx,-0x10(%rbp) lea 0x2ba5(%rip),%rdxs mov -0x8(%rbp),%rax mov %rdx,(%rax) mov -0x8(%rbp),%rax mov -0xc(%rbp),%edx mov %edx,0x8(%rax) mov -0x8(%rbp),%rax mov -0x10(%rbp),%edx mov %edx,0xc(%rax) pop %rbp ret <_ZN5test14infoEv>: # test1::info() push %rbp mov %rsp,%rbp sub $0x10,%rsp mov %rdi,-0x8(%rbp) mov -0x8(%rbp),%rax mov 0x8(%rax),%edx mov -0x8(%rbp),%rax mov 0xc(%rax),%eax cmp %eax,%edx jle 1239 <_ZN5test14infoEv+0x27> mov -0x8(%rbp),%rax mov 0x8(%rax),%eax jmp 1240 <_ZN5test14infoEv+0x2e> mov -0x8(%rbp),%rax mov 0xc(%rax),%eax mov %eax,%esi lea 0xdbb(%rip),%rdi mov $0x0,%eax call 1030 <printf@plt> leave ret <_ZN5test2C1Eii>: # test2 构造函数 push %rbp mov %rsp,%rbp sub $0x10,%rsp mov %rdi,-0x8(%rbp) mov %esi,-0xc(%rbp) mov %edx,-0x10(%rbp) mov -0x8(%rbp),%rax mov -0x10(%rbp),%edx mov -0xc(%rbp),%ecx mov %ecx,%esi mov %rax,%rdi call 11de <_ZN5test1C1Eii> lea 0x2afd(%rip),%rdx mov -0x8(%rbp),%rax mov %rdx,(%rax) leave ret <_ZN5test24infoEv>: # test2::info() push %rbp mov %rsp,%rbp sub $0x10,%rsp mov %rdi,-0x8(%rbp) mov -0x8(%rbp),%rax mov 0x8(%rax),%edx mov -0x8(%rbp),%rax mov 0xc(%rax),%eax cmp %eax,%edx jge 12b5 <_ZN5test24infoEv+0x27> mov -0x8(%rbp),%rax mov 0x8(%rax),%eax jmp 12bc <_ZN5test24infoEv+0x2e> mov -0x8(%rbp),%rax mov 0xc(%rax),%eax mov %eax,%esi lea 0xd47(%rip),%rdi mov $0x0,%eax call 1030 <printf@plt> leave ret
笔者本段代码中 main() 的汇编语言描述提供了十分详细的注释,相信读者可根据注释自行理解.
C++ 众多编译器都采用虚函数表的方式实现了 C++ 的虚函数调用.在本例中,gcc 自然也没有什么例外的使用虚函数表实现 C++ 的虚函数功能.
虚函数表可以理解为一个函数指针的数组.编译器需要为含有虚函数的类型生成一张虚函数表,而同一个类型的多个实例将通过存储虚函数表的首元素的地址共享同一张虚函数表.
1 2 3 4 5 6 7 class test1 { static const void *virtualFunctionTable[SIZE]; int a; int b; };
此处只是一个粗略的描述,所以笔者采用了 void *virtualFunctionTable[SIZE]; 这种写法,实际上这种写法很不严谨.void (*virtualFunctionTable[SIZE])(); 这种写法并不能更好.写成 void* 首先较为方便,并且避免读者纠结于类似「void (*func)(int *a,int b);」这种函数指针不能存放在 void (*virtualFunctionTable[SIZE])() 这类次要问题.请务必注意这只是一个为了方便理解虚函数表,笔者给出的伪代码而已.
参考资料 1 . 段刚.加密与解密[M].第4版.北京:电子工业出版社. ↩ 2 . KipIrvine.汇编语言:基于x86处理器[M].原书第7版.贺莲,译.北京:机械工业出版社. ↩ 3 . Randal E.Bryant.深入理解计算机系统[M].第三版.龚奕利,译.北京:机械工业出版社. ↩ 4 . x64 calling convention[G/OL]. docs.microsoft.com. https://docs.microsoft.com/en-us/cpp/build/x64-calling-convention?view=msvc-160 . ↩ 5 . 维基百科编者. X86调用约定[G/OL]. 维基百科. 2020(20200922)[2020-09-22]. https://zh.wikipedia.org/zh-hans/X86调用约定 . ↩ 6 . WikipediaContributors. X86调用约定[G/OL]. 维基百科. 2020(20200922)[2020-09-22]. https://en.wikipedia.org/wiki/X86_calling_conventions . ↩