网络拾遗--IPv6 地址自动配置
前言
近年来,就 Y7n05h 的主观体验来说,虽然 IPv4 地址资源耗尽早已不是什么新鲜的话题,但 IPv6 的发展一直处于不温不火的境地。
也许海外地区对 IPv6 的应用更为广泛,这一点 Y7n05h 就不得而知了,因此也不做过多的讨论。
在 Y7n05h 通过发布匿名调查问卷中,截止 2023-01-07T19:57+00:00 得到了 97 位受访者的对 IPv6 的普及情况的一些统计信息:
- 仅有 46% 的受访者表示自己的所有家庭网络设备支持 IPv6
- 仅有 58% 的受访者表示自己的运营商提供了 IPv6 的接入
- 仅有 13% 的受访者表示自己喜欢或常用的服务全部支持 IPv6 访问
- 仍有 29% 的受访者表示自己仅使用 IPv4,不使用 IPv6
- 没有任何受访者表示自己仅使用 IPv6 不使用 IPv4
注:
- 上述统计信息仍在进行,且受访者可随时更改自己已提交的答案,因此以上信息仅针对 2023-01-07T19:57+00:00 时的统计结果。
- Y7n05h 无法对受访者提交的信息的真实性、准确性做出核实,上述内容仅供参考。
根据以上统计信息,纵使多年过去,IPv6 的普及情况依旧不容乐观。
IPv6 与 IPv4 最大的不同(当然也是最众所周知的不同)那当然是在地址长度上。IPv6 通过 16 bytes 的地址长度与 IPv4 的 4 bytes 地址长度相比仅仅增长原来的 3 倍,但能提供的地址数量却增长了 95 倍,号称能为世界上的每一粒沙子分配一个 IPv6 地址。
通过扩充地址长度,IPv6 确实从根本上解决了 IPv4 地址耗尽的问题。
不但如此,IPv6 还通过取消了 IPv4 中的校验和、取消 IPv4 中的 Options、取消了 IPv4 中的分片 简化了软硬件实现的复杂度。
对 IPv4 而言 ARP、DHCP、ICMP 也是在通信过程中重要的一环,遗憾的是,IPv6 对这里做出了很多改变。
存在 DHCPv6、ICMPv6 这两种协议,但却并不存在 ARPv6 这种看似应该存在的东西。另外,除了 DHCPv6 之外,IPv6 还有其他用来配置 IP 的方式。
诸如此类的细节改动还有取消广播,优化任播、组播等等。这些改动修正了 IPv4 中的很多问题,也让网络层协议更加精简。
IPv6 与 IPv4 的更多差异可查阅 与IPv4 比较。
IPv6 带来了足够多的优化,但究竟是什么让 IPv6 的普及困难重重?
Y7n05h 曾一度认为是 40 bytes IPv6 header,让习惯了迷你的只有 20 bytees IPv4 header 的用户无法适应,认为其中存在性能问题。
但,这一观点其实也很难成立。在 vxlan 这种巨大的 overhead 面前,IPv6 相比 IPv4 多出来的 20 bytes 实在算是迷你。
而 vxlan 早都在生产环境中大量使用了。万兆、2.5 G 网络甚至都在家庭用户中普及(更别提数据中心的网络又进一步升级到了何等程度)。所以对 IPv6 带来的额外的 20 bytes 开销过于担心可能是多余的。
那么 IPv6 的普及困难或许和开发者不愿处理双栈带来的程序复杂度上升有关,毕竟与 IPv6 这位新友相比 IPv4 绝对称得上故旧了,开发者们基于降低程序复杂度的考虑不去支持 IPv6 也不算奇怪。
另一方面,可能与运营商对 IPv6 网络支持仍旧不如 IPv4 有关。
IPv6 地址分类
单播地址
下面是部分常见的 IPv6 单播地址分类,更多详细类别可查看IPv6 单播特殊地址:
| 分类 | 范围 | 说明 |
|---|---|---|
| 全球单播地址 Global Unicast Address | 2000::/3 | 作用类似「IPv4 公网地址」 |
| 链路本地地址 Link Local Address | fe80::/10 | 仅在链路内有效 |
| 站点本地地址 Site Local Address | fec0::/10 | 已被 RFC3879 废弃 |
| 唯一本地地址 Unique Local Address | fc00::/7 | 作用类似「IPv4 私网地址」 |
| 未指定地址 Unspecified Address | ::/128 | 作用类似 0.0.0.0/32 |
| 回环地址 Loopback Address | ::1/128 | 作用类似 127.0.0.0/8 |
有效范围:全球单播 > 唯一本地 > 链路本地
组播地址
IPv6 多播地址都位于:ff00::/8。
组播也在 IPv6 通信过程中发挥重要作用,但本文无意过多涉及组播相关内容。
在此,笔者仅列出几个出现在本文后续内容中的组播地址,更多内容可以查看 IPv6 多播地址:
- ff02::1 All nodes on the local network segment
- ff02::2 All routers on the local network segment
- ff02::1:ff00:0/104 Solicited-node multicast address
被请求节点组播地址(Solicited-node multicast address)将在 DaD(Duplicate address detection) 中使用。要得到一个 IPv6 单播地址对应的 被请求节点组播地址(Solicited-node multicast address)只需要让 ff02::1:ff00:0 与 IPv6 地址的高 24 bits 按位与即可。
IPv6 地址自动配置的过程
TIP
本节内容是对 IPv6 地址自动配置流程的总体叙述。本节中提及的 Stateless、Stateful 将在后文说明。
下面是 IPv6 地址自动配置中的流程,其中缺少了 DaD(Duplicate address detection)相关的流程。
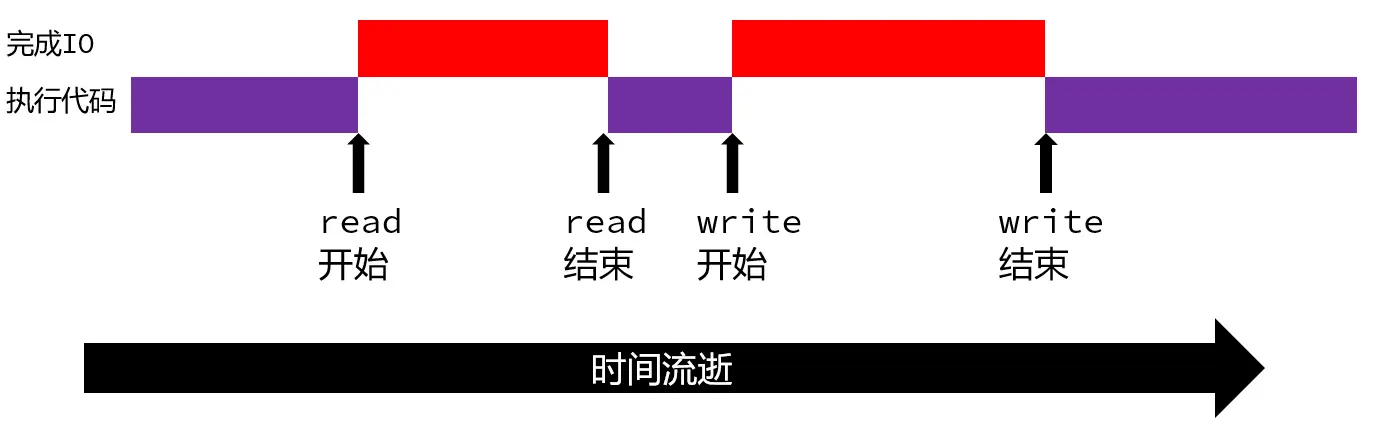
![IPv6 地址自动配置流程\[1\]](/img/ipv6-addr-flow.webp)
下图是在 IPv6 网络地址自动配置过程中通过 Wireshark 进行抓包分析得到的数据:


可以看到编号 6-22 的包是在进行地址的自动配置,其中:
- No.6 是在对通过 Stateless 方式配置得到的 Link Local Adress 进行 DaD
- No.18 和 No.19 为请求并获得 RA 报文
- No.21 和 No.22 则是对通过 Stateless 方式配置的两个 Global Unicast Address 进行 DaD
地址自动配置方法分类
本地链路地址配置 Link Local Address
Link Local Address 能通过两种方式完成配置:
- 手动配置
- Stateless 地址自动配置
全球单播地址 Global Unicast Address / 唯一本地地址 Unique Local Address 自动配置
全球单播地址 Global Unicast Address 和 唯一本地地址 Unique Local Address 的配置并无区别。
这个标题听起来复杂,但简而言之:
新上线的设备通过一定的策略挑一个 IP 出来使用,准备使用之前,新上线的设备先对欲使用的 IP 执行 DAD,看看这个 IP 是否已经被别的设备使用,如果没被别的设备端占用那就用它。
这个策略总体上分三类,也就是:
- 手动配置
- Stateless 地址自动配置
- Stateful 地址自动配置
手动配置自然不必多提,下面我们讨论两种自动配置的方法。
Stateless 地址自动配置(Stateless Address Auto-configuration,SLAAC)
Stateless 意味着没有控制中心,没有一个 controller 来负责管理 IP 地址的分配。IP 地址由设备自己选择。
常见的 Stateless 地址自动配置方式由:
- Modified EUI-64
- Random
EUI-64 将网卡的 MAC 地址加以修改并和从 RA 报文中获得的 Prefix information 按位与就能得到 IP 地址。
Random 则随即挑选一个值,并把它和从 RA 报文中获得的 Prefix information 按位与就能得到 IP 地址。
Stateful 地址自动配置(Stateful Address Auto-configuration)
Stateless 意味着有控制中心,有一个 controller 来负责管理 IP 地址的分配。IP 地址由设备自己选择。
相信此时一定想起来了 IPv4 的 DHCP 完美符合这个需求。对的,对 IPv6 而言,Stateful 就意味着 DHCPv6。
常见的 Stateful 方式有两种:
- Stateful DHCPv6
- Stateless DHCPv6
这二者又有什么区别?
Stateful DHCPv6 意味着使用从 DHCPv6 获得的所有信息。
Stateless DHCPv6 则意味着使用 Stateless 的方式生成 IPv6 的地址,但从 DHCPv6 中获取网络的其他信息(例如 DNS)。
路由器通告(Router Advertisement,RA)
链路中的 Router 会定期向 ff02::1 组播 RA 报文。新加入链路的设备为了立即获得 RA 报文,通常回向 ff02::2 组播 RS(Router Solicitation) 报文,使得 Router 回复 RA 报文。
这是前文在抓包过程中得到的 RA 报文。
RA 报文里面包含了 Prefix information 用来在 SLAAC 时生成 IP 地址(前文已说明)。
Prefix information 含有一下 flags:
Flag: 0xc0, On-link flag(L), Autonomous address-configuration flag(A)
1… …. = On-link flag(L): Set
.1.. …. = Autonomous address-configuration flag(A): Set
..0. …. = Router address flag(R): Not set
…0 0000 = Reserved: 0
其中的 A flag 对 IPv6 地址自动配置有较大影响:
- A:若 A flag 被设置则需要为当前 Prefix 通过 SLAAC 配置 IP 地址。(无论 A flag 是否设置,都需要为当前 Prefix 设置路由表)
对于 Router Advertisement 中的 flags 则需要关注:
Flags: 0x08, Prf (Default Router Preference): High
0… …. = Managed address configuration: Not set
.0.. …. = Other configuration: Not set
..0. …. = Home Agent: Not set
…0 1… = Prf (Default Router Preference): High (1)
…. .0.. = Proxy: Not set
…. ..0. = Reserved: 0
- M:Managed address configuration
- O:Other configuration
若 M == true 都被设置则使用 Stateful DHCPv6 完成地址配置。
若 ( M == false && O == true ) 则使用 Stateless DHCPv6 完成地址配置。
若 ( M == false && O == false ) 则使用 Stateful 完成地址配置。
对 RA 报文更详细的说明可查阅:ICMPv6 RA 和 RS 报文。(注:这里的文档有些陈旧,缺少了 RA 报文对 DNS 的支持的信息。)
邻居通告(Neighbor Advertisement,NA)
邻居请求报文(Neighbor Solicitation,NS)和邻居通告报文(Neighbor Advertisement,NA)的作用类似 IPv4 中的 ARP Request 和 ARP Reply。
与 ARP Request 使用广播不同,NS 通过向请求 IP 的被请求节点组播地址(Solicited-node multicast address)进行组播。网卡能对组播报文进行过滤,仅接受需要的组播报文,比广播机制更加高效。
NA 报文常常被用作重复地址检测(Duplicate address detection),当一个设备正试图使用一个 IP 地址时,将会向其对应的被请求节点组播地址组播 NS 报文,请求解析该 IP 地址的 MAC 地址。在一定时间内,若未能收到回复,则说明链路上不存在使用这个 IP 的设备;反之则说明该 IP 已被使用。通过任意一种方式配置的 IPv6 地址,设备都会对其进行重复地址检测。
参考资料
- https://www.cnblogs.com/fzxiaomange/p/ipv6-autoconf-stateless-stateful.html
- https://www.rfc-editor.org/rfc/rfc4861
- https://en.wikipedia.org/wiki/Solicited-node_multicast_address
- https://www.iana.org/assignments/icmpv6-parameters/icmpv6-parameters.xhtml#icmpv6-parameters-5
- http://www.tcpipguide.com/free/t_ICMPv6RouterAdvertisementandRouterSolicitationMess-2.htm