Clang Thread Safety Analysis is a C++ language extension which warns about potential race conditions in code. The analysis is completely static (i.e. compile-time); there is no run-time overhead. The analysis is still under active development, but it is mature enough to be deployed in an industrial setting. It is being developed by Google, in collaboration with CERT/SEI, and is used extensively in Google’s internal code base.
Thread safety analysis works very much like a type system for multi-threaded programs. In addition to declaring the type of data (e.g. int, float, etc.), the programmer can (optionally) declare how access to that data is controlled in a multi-threaded environment. For example, if foo is guarded by the mutex mu, then the analysis will issue a warning whenever a piece of code reads or writes to foo without first locking mu. Similarly, if there are particular routines that should only be called by the GUI thread, then the analysis will warn if other threads call those routines.[3]
Valgrind is an instrumentation framework for building dynamic analysis tools. There are Valgrind tools that can automatically detect many memory management and threading bugs, and profile your programs in detail. You can also use Valgrind to build new tools.
The Valgrind distribution currently includes seven production-quality tools: a memory error detector, two thread error detectors, a cache and branch-prediction profiler, a call-graph generating cache and branch-prediction profiler, and two different heap profilers. It also includes an experimental SimPoint basic block vector generator. It runs on the following platforms: X86/Linux, AMD64/Linux, ARM/Linux, ARM64/Linux, PPC32/Linux, PPC64/Linux, PPC64LE/Linux, S390X/Linux, MIPS32/Linux, MIPS64/Linux, X86/Solaris, AMD64/Solaris, ARM/Android (2.3.x and later), ARM64/Android, X86/Android (4.0 and later), MIPS32/Android, X86/Darwin and AMD64/Darwin (Mac OS X 10.12).
spdlog:Very fast, header-only/compiled, C++ logging library.
Google Logging Library:Google Logging (glog) is a C++98 library that implements application-level logging. The library provides logging APIs based on C++-style streams and various helper macros.
/* call3.c */ voidfunc1() { } intfunc3(int a, int b, int c, int d, int e, int f, int g, int h, int i, int j) { func1(); return a * 1 + b * 2 + c * 3 + d * 4 + e * 5 + f * 6 + g * 7 + h * 8 + i * 9 + j * 10; } intmain() { func3(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); }
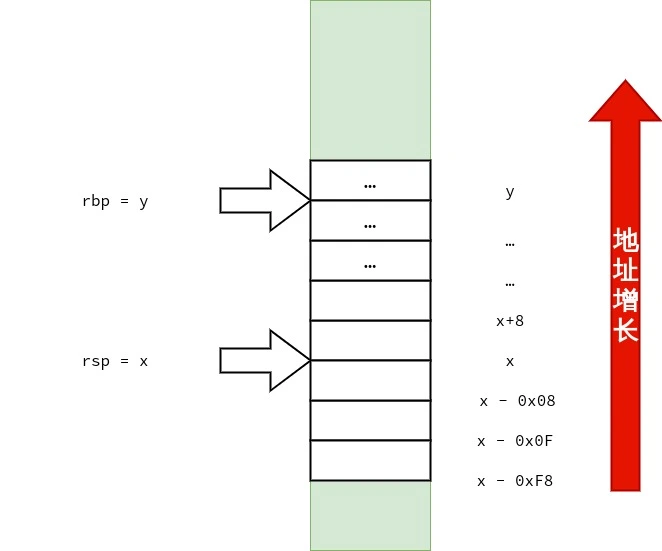
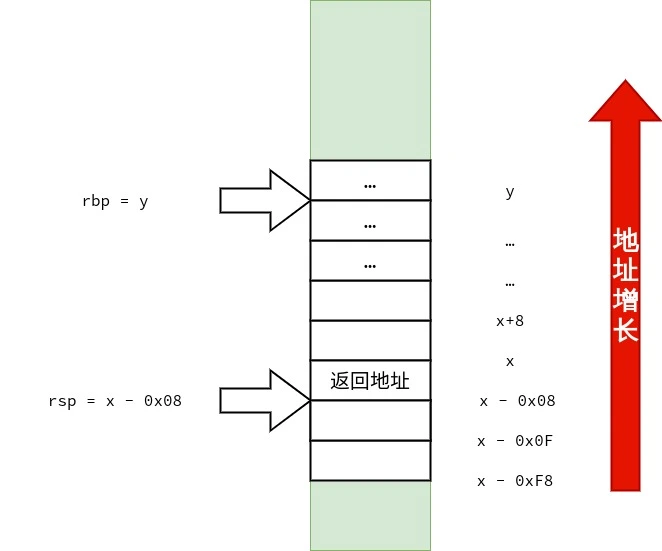
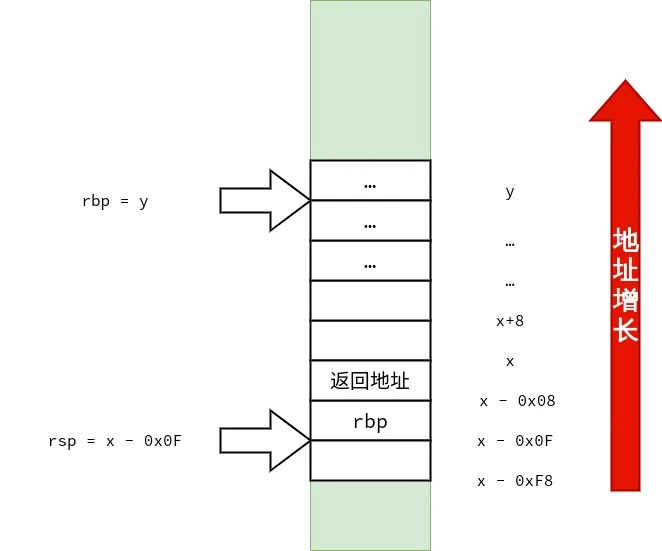
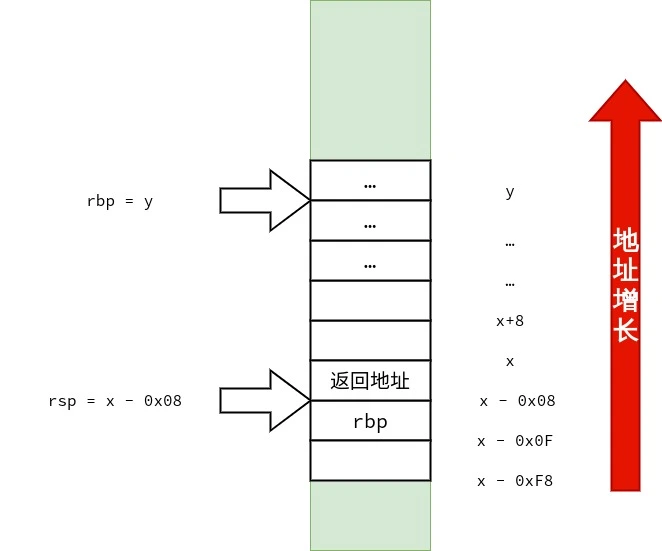
首先,笔者要声明的是:调用约定与设备的 ABI(application binary interface)有关,而 ABI 依赖「硬件特性」与「操作系统」.在 x86-64 上也不只有一种调用约定.
Microsoft x64 calling convention
这张表展示了 Microsoft x64 calling convention 的部分内容,笔者展示这张表的目的不在于向读者介绍 Microsoft x64 calling convention 的具体内容,仅仅是为了说明调用约定不止一种.当遇到与笔者接下来介绍的 System V AMD64 ABI 不同的调用约定时,也不要对此感到惊奇和诧异.
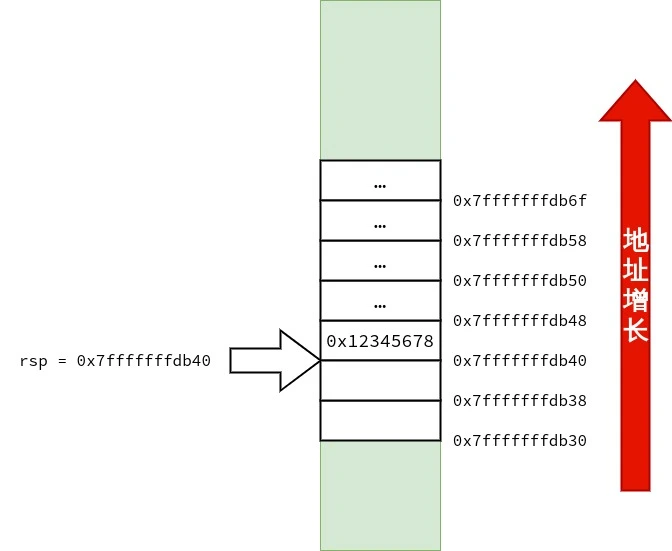
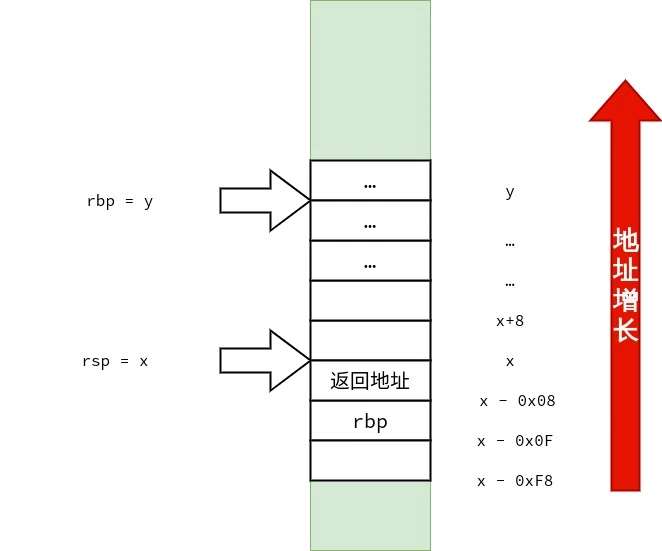
众所周知,C++ 的非静态成员函数有一个隐式的参数就是 *this 指向成员函数所在的类的类型的指针. 例如: 在考虑 C++ 与汇编代码的关系时,可以将本例中 sum 的理解为:
1 2 3 4
intsum(class test *this) { returnthis->a + this->b; }
简而言之,C++ 非静态非虚成员函数含有一个隐式的 this 指针参数,作为第一个参数传递.
这与上文所说的一致.
「第一个小于等于 8 bytes 的整形参数在 System V AMD64 ABI」通过 rdi 传递
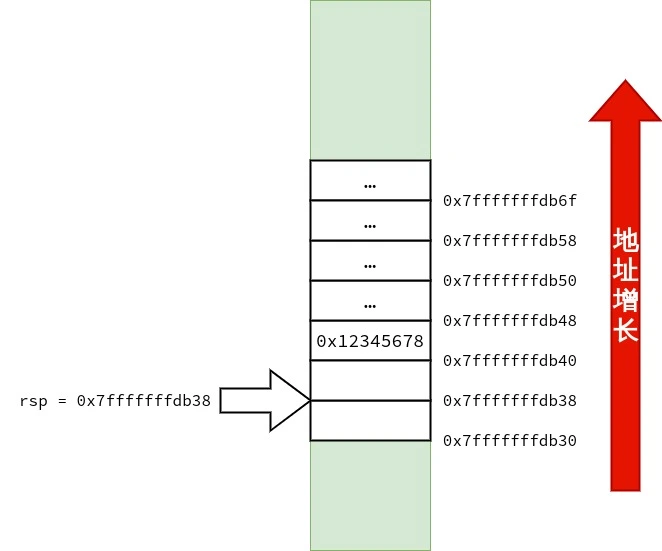
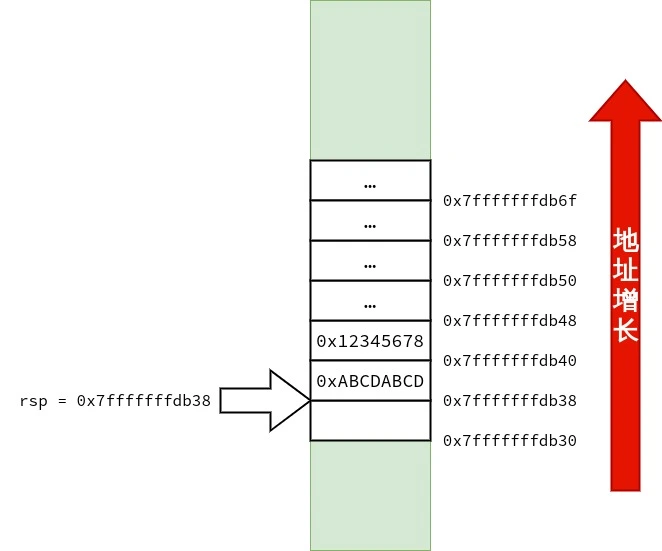
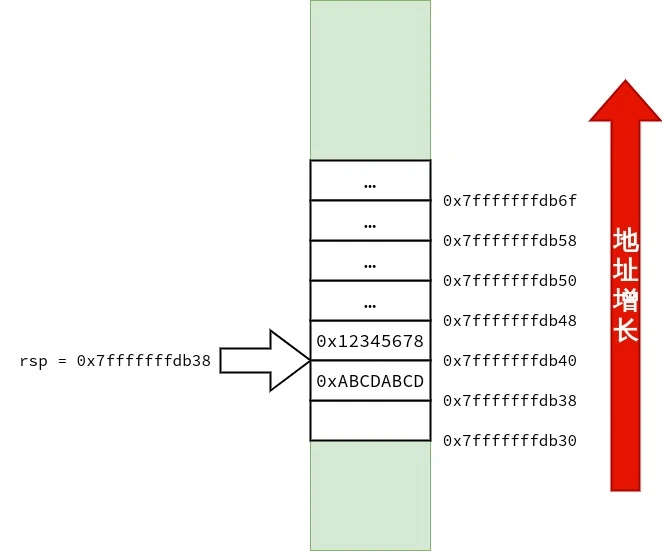
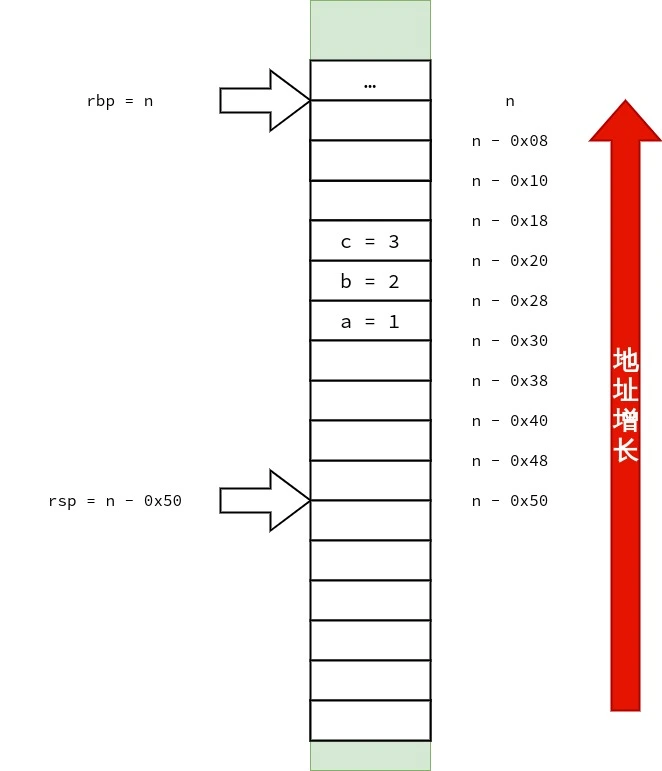
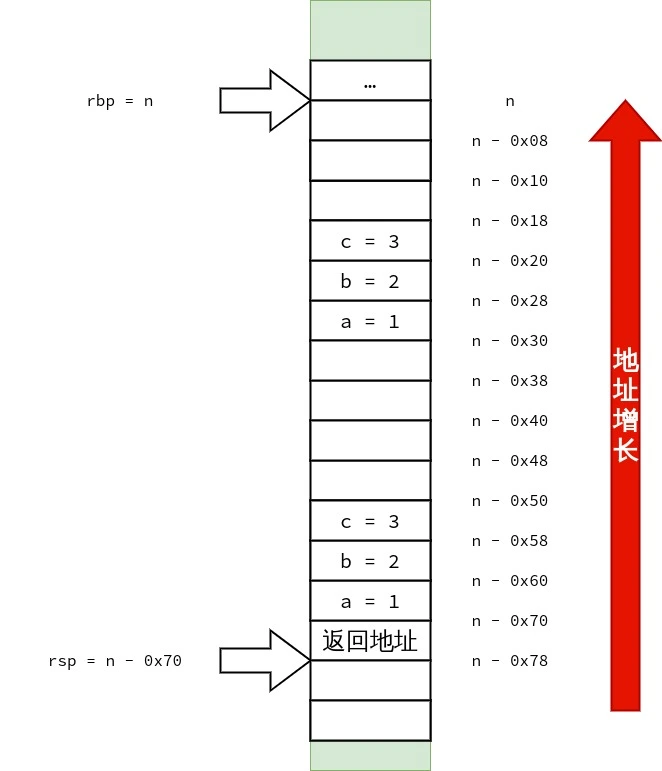
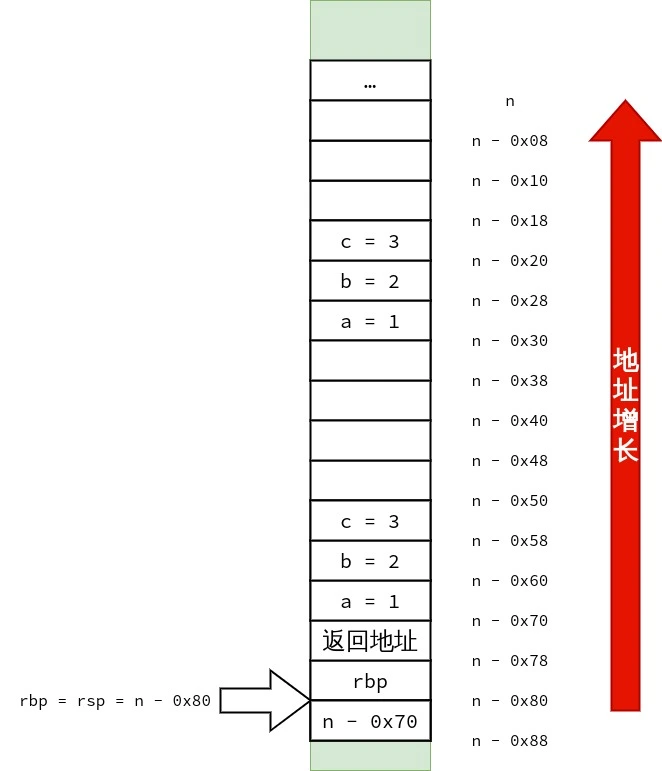
好,现在尝试增多 C++ 非静态非虚成员函数 的参数数量.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#include<cstdio> classtest { int a, b;
public: test() = default; intsum2(int u, int v, int w, int x, int y, int z) { return a + b + u + v + w + x + y + z; } }; intmain() { test t; int s = t.sum2(1, 2, 3, 4, 5, 6); printf("%d\n", s); }
if (SINGLE_THREAD_P)// 是单线程 { return _int_malloc(&main_arena, bytes); }
进入 _int_malloc()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size returns false for request sizes that are so large that they wrap around zero when padded and aligned. */
if (!checked_request2size(bytes, &nb))// 根据 bytes 、元数据大小、对齐要求计算 nb { __set_errno(ENOMEM); returnNULL; }
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from mmap. */ if (__glibc_unlikely(av == NULL)) { void *p = sysmalloc(nb, av);// av 不存在,向 system 申请更多的 memory if (p != NULL) alloc_perturb(p, bytes); return p; }
if ((unsignedlong) (nb) <= (unsignedlong) (get_max_fast()))// get_max_fast() 默认值为 DEFAULT_MXFAST { // 因为 nb 是对齐的,当 nb <= get_max_fast() 时,必为 fastbin 的合法大小.不存在 nb 不超过 get_max_fast() 却无 fastbin_index 与之对应的情况. idx = fastbin_index(nb); mfastbinptr *fb = &fastbin(av, idx); mchunkptr pp; victim = *fb;
if (victim != NULL) {//对应的 fastbin 不为空 if (__glibc_unlikely(misaligned_chunk(victim))) malloc_printerr("malloc(): unaligned fastbin chunk detected 2");
if (SINGLE_THREAD_P) //单线程 *fb = REVEAL_PTR(victim->fd);// 删除第一个节点.REVEAL_PTR 是为了提高安全性,抵抗恶意攻击. else// 多线程 REMOVE_FB(fb, pp, victim); if (__glibc_likely(victim != NULL)) { size_t victim_idx = fastbin_index(chunksize(victim));// 本行的计算是为了下一行的 assert if (__builtin_expect(victim_idx != idx, 0)) malloc_printerr("malloc(): memory corruption (fast)"); check_remalloced_chunk(av, victim, nb);// malloc_debug 的 assert #if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx(nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = *fb) != NULL) { if (__glibc_unlikely(misaligned_chunk(tc_victim))) malloc_printerr("malloc(): unaligned fastbin chunk detected 3"); if (SINGLE_THREAD_P) *fb = REVEAL_PTR(tc_victim->fd); else { REMOVE_FB(fb, pp, tc_victim); if (__glibc_unlikely(tc_victim == NULL)) break; } tcache_put(tc_victim, tc_idx); } } #endif void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; } }//对应的 fastbin 为空 }
/* If a small request, check regular bin. Since these "smallbins" hold one size each, no searching within bins is necessary. (For a large request, we need to wait until unsorted chunks are processed to find best fit. But for small ones, fits are exact anyway, so we can check now, which is faster.) */
if (in_smallbin_range(nb)) {// 准确的表述为:不满足 LargeBin 分配的最小值
//值得注意的是:在fastbin 环节分配失败会进入此处. idx = smallbin_index(nb); bin = bin_at(av, idx);
if (av != &main_arena) set_non_main_arena(victim); check_malloced_chunk(av, victim, nb); #if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx(nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = last(bin)) != bin) { if (tc_victim != 0) { bck = tc_victim->bk; set_inuse_bit_at_offset(tc_victim, nb); if (av != &main_arena) set_non_main_arena(tc_victim); bin->bk = bck; bck->fd = bin;
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */
/* If a large request, scan through the chunks of current bin in sorted order to find smallest that fits. Use the skip list for this. */
//是 大请求 if (!in_smallbin_range(nb)) { bin = bin_at(av, idx);
/* skip scan if empty or largest chunk is too small */ if ((victim = first(bin)) != bin && (unsignedlong) chunksize_nomask(victim) >= (unsignedlong) (nb)) { victim = victim->bk_nextsize;//victim 现在指向最小的 chunk while (((unsignedlong) (size = chunksize(victim)) < (unsignedlong) (nb))) victim = victim->bk_nextsize;
// 两个 chunk 一样大,用第二个 chunk ??? /* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last(bin) && chunksize_nomask(victim) == chunksize_nomask(victim->fd)) victim = victim->fd;
// UnsortBin 最多只遍历 MAX_ITERS 次,无法保证为空 /* We cannot assume the unsorted list is empty and therefore have to perform a complete insert here. */ bck = unsorted_chunks(av); fwd = bck->fd; if (__glibc_unlikely(fwd->bk != bck)) malloc_printerr("malloc(): corrupted unsorted chunks"); remainder->bk = bck;//在 UnsortBin 的头节点之后插入剩余 chunk remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; if (!in_smallbin_range(remainder_size)) {//如果不是 SmallChunk 则将 fd_next bk_next 置为 NULL remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); } check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; } }
若 nb 不在 SmallBin 范围内,则从 LargeBin 中寻找最合适的chunk(大于等于 nb 的最小 chunk). 若最合适的 chunk 的大小大于 nb + MINSIZE 则进行分割,剩余部分放在 UnsortBin 中.之后返回切分出的 chunk 对应的指针.结束分配流程.
其他情况
1 2 3 4 5 6 7 8 9 10 11 12 13
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected. The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */
++idx; bin = bin_at(av, idx); block = idx2block(idx); map = av->binmap[block]; bit = idx2bit(idx);
if (in_smallbin_range(nb)) {// 准确的表述为:不满足 LargeBin 分配的最小值
//在fastbin 环节分配失败会进入此处. idx = smallbin_index(nb); bin = bin_at(av, idx);// bin 是头节点的指针
/* 有删节 */ }
/* If this is a large request, consolidate fastbins before continuing. While it might look excessive to kill all fastbins before even seeing if there is space available, this avoids fragmentation problems normally associated with fastbins. Also, in practice, programs tend to have runs of either small or large requests, but less often mixtures, so consolidation is not invoked all that often in most programs. And the programs that it is called frequently in otherwise tend to fragment. */
/* Conservatively use 32 bits per map word, even if on 64bit system */ #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) #define BINMAPSIZE (NBINS / BITSPERMAP)
for (;;) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) {//??? do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ((map = av->binmap[block]) == 0);
bin = bin_at(av, (block << BINMAPSHIFT)); bit = 1; }
/* Advance to bin with set bit. There must be one. */ while ((bit & map) == 0) { bin = next_bin(bin); bit <<= 1; assert(bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ victim = last(bin);
/* If a false alarm (empty bin), clear the bit. */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin(bin); bit <<= 1; }
else { size = chunksize(victim);
/* We know the first chunk in this bin is big enough to use. */ assert((unsignedlong) (size) >= (unsignedlong) (nb));
remainder_size = size - nb;
/* unlink */ unlink_chunk(av, victim);
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) set_non_main_arena(victim); }
use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations). We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise beexhausted by current request, it is replenished. (The mainreason for ensuring it exists is that we may need MINSIZE spaceto put in fenceposts in sysmalloc.) */
victim = av->top; size = chunksize(victim);
if (__glibc_unlikely(size > av->system_mem)) malloc_printerr("malloc(): corrupted top size");
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (atomic_load_relaxed(&av->have_fastchunks)) { malloc_consolidate(av); /* restore original bin index */ if (in_smallbin_range(nb)) idx = smallbin_index(nb); else idx = largebin_index(nb); }
#ifdef USE_MTAG /* Quickly check that the freed pointer matches the tag for the memory. This gives a useful double-free detection. */ *(volatilechar *) mem; #endif
int err = errno;
p = mem2chunk(mem);
/* Mark the chunk as belonging to the library again. */ (void) TAG_REGION(chunk2rawmem(p), CHUNK_AVAILABLE_SIZE(p) - CHUNK_HDR_SZ);
if (chunk_is_mmapped(p)) /* release mmapped memory. */ { /* See if the dynamic brk/mmap threshold needs adjusting. Dumped fake mmapped chunks do not affect the threshold. */ if (!mp_.no_dyn_threshold && chunksize_nomask(p) > mp_.mmap_threshold && chunksize_nomask(p) <= DEFAULT_MMAP_THRESHOLD_MAX && !DUMPED_MAIN_ARENA_CHUNK(p)) { mp_.mmap_threshold = chunksize(p); mp_.trim_threshold = 2 * mp_.mmap_threshold; LIBC_PROBE(memory_mallopt_free_dyn_thresholds, 2, mp_.mmap_threshold, mp_.trim_threshold); } munmap_chunk(p); } else { MAYBE_INIT_TCACHE();
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect(misaligned_chunk(p), 0)) malloc_printerr("free(): invalid pointer"); /* We know that each chunk is at least MINSIZE bytes in size or a multiple of MALLOC_ALIGNMENT. */ if (__glibc_unlikely(size < MINSIZE || !aligned_OK(size))) malloc_printerr("free(): invalid size");
if ((unsignedlong) (size) <= (unsignedlong) (get_max_fast())
#if TRIM_FASTBINS /* If TRIM_FASTBINS set, don't place chunks bordering top into fastbins */ && (chunk_at_offset(p, size) != av->top) #endif ) {
if (__builtin_expect(chunksize_nomask(chunk_at_offset(p, size)) <= CHUNK_HDR_SZ, 0) || __builtin_expect(chunksize(chunk_at_offset(p, size)) >= av->system_mem, 0)) { bool fail = true; /* We might not have a lock at this point and concurrent modifications of system_mem might result in a false positive. Redo the test after getting the lock. */ if (!have_lock) { __libc_lock_lock(av->mutex); fail = (chunksize_nomask(chunk_at_offset(p, size)) <= CHUNK_HDR_SZ || chunksize(chunk_at_offset(p, size)) >= av->system_mem); __libc_lock_unlock(av->mutex); }
if (fail) malloc_printerr("free(): invalid next size (fast)"); }
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */ mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P) {//单线程 /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect(old == p, 0))//安全检查 malloc_printerr("double free or corruption (fasttop)"); /* 在 FastBin 链表的头指针处 */ p->fd = PROTECT_PTR(&p->fd, old);//为阻碍恶意攻击,把 &p->fd 处理后存到 old *fb = p; } else//多线程 do { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect(old == p, 0)) malloc_printerr("double free or corruption (fasttop)"); old2 = old; p->fd = PROTECT_PTR(&p->fd, old); } while ((old = catomic_compare_and_exchange_val_rel(fb, p, old2)) != old2);
/* Check that size of fastbin chunk at the top is the same as size of the chunk that we are adding. We can dereference OLD only if we have the lock, otherwise it might have already been allocated again. */ if (have_lock && old != NULL && __builtin_expect(fastbin_index(chunksize(old)) != idx, 0)) malloc_printerr("invalid fastbin entry (free)"); }
victim = _int_malloc(ar_ptr, bytes); /* Retry with another arena only if we were able to find a usable arena before. */ if (!victim && ar_ptr != NULL) { LIBC_PROBE(memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry(ar_ptr, bytes); victim = _int_malloc(ar_ptr, bytes); }
if (ar_ptr != NULL) __libc_lock_unlock(ar_ptr->mutex);
#if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx(nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = *fb) != NULL) { if (__glibc_unlikely(misaligned_chunk(tc_victim))) malloc_printerr("malloc(): unaligned fastbin chunk detected 3"); if (SINGLE_THREAD_P) *fb = REVEAL_PTR(tc_victim->fd); else { REMOVE_FB(fb, pp, tc_victim); if (__glibc_unlikely(tc_victim == NULL)) break; } tcache_put(tc_victim, tc_idx); } } #endif
/* Caller must ensure that we know tc_idx is valid and there's room for more chunks. */ static __always_inline voidtcache_put(mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *) chunk2mem(chunk);
/* Mark this chunk as "in the tcache" so the test in _int_free will detect a double free. */ e->key = tcache;
#if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx(nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = last(bin)) != bin) { if (tc_victim != 0) { bck = tc_victim->bk; set_inuse_bit_at_offset(tc_victim, nb); if (av != &main_arena) set_non_main_arena(tc_victim); bin->bk = bck; bck->fd = bin;
#if USE_TCACHE /* If we've processed as many chunks as we're allowed while filling the cache, return one of the cached ones. */ ++tcache_unsorted_count; if (return_cached && mp_.tcache_unsorted_limit > 0 && tcache_unsorted_count > mp_.tcache_unsorted_limit) { return tcache_get(tc_idx); } #endif
1 2 3 4 5 6
#if USE_TCACHE /* If all the small chunks we found ended up cached, return one now. */ if (return_cached) { return tcache_get(tc_idx); } #endif
这两段代码是如此的相似,都先检查了 return_cached (第一段还检查了其他的条件),满足则从 tcache 中取出 nb 对应的 chunk,并将其返回.
#if USE_TCACHE { size_t tc_idx = csize2tidx(size); if (tcache != NULL && tc_idx < mp_.tcache_bins) { /* Check to see if it's already in the tcache. */ tcache_entry *e = (tcache_entry *) chunk2mem(p);
/* This test succeeds on double free. However, we don't 100% trust it (it also matches random payload data at a 1 in 2^<size_t> chance), so verify it's not an unlikely coincidence before aborting. */ if (__glibc_unlikely(e->key == tcache)) { tcache_entry *tmp; size_t cnt = 0; LIBC_PROBE(memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = REVEAL_PTR(tmp->next), ++cnt) { if (cnt >= mp_.tcache_count) malloc_printerr("free(): too many chunks detected in tcache"); if (__glibc_unlikely(!aligned_OK(tmp))) malloc_printerr("free(): unaligned chunk detected in tcache 2"); if (tmp == e) malloc_printerr("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ } }
graph TD BEGIN-->__libc_malloc[\__libc_mallloc\] __libc_malloc-->A A[分配 x bytes 内存] --> B[计算所需 chunk 大小 tbytes]; B --> C[计算 tcache 下标 tc_idx]; C --> D[tcache 对应链表非空]; D -- True --> tcache_get[\tcache_get\] tcache_get --> E[返回指针]; E --> END; D -- False --> F{单线程?}; F -- True --> G1[\_int_malloc\] F -- False --> H[arena_get 为 arena 加锁] H --> G2[\_int_malloc\] G2 --> L{分配成功?} L -- True -->I[解锁 arena] L -- False -->M[更换 arean] M --> G3[\_int_malloc\] G3 -->I I --> E G1 -->E;
整体流程
-->
_int_malloc
Init 计算需要分配的 chunk 大小
sysmalloc:若无合适的 arena 则调用 sysmalloc 通过 mmap 分配
Fast Bin:相同 chunk 大小、LIFO 顺序,取出头节点
tcache:若在 FastBin 中分配成功,将同 Fast Bin 中的 chunk 头插入 tcache
Small Bin:取出尾节点
tcache:若在 SmallBin 中分配成功,将同 Small Bin 中的 chunk 头插入 tcache
Unsorted Bin:
特殊规则:对于 Small Bin 范围内的请求,当 Unsorted Bin 仅剩唯一 chunk 且该 chunk 来源于 last remainder,进行分配(能切则切)
查找大小相同的 chunk,头插入 tcache,直到 tcache 满
大小不同的 chunk 按照大小插入 Large Bin(按照大小,相同大小则将当前 chunk 插入在第 2 个) 或者 Small Bin(头插)
tcache 满了后则从 Unsorted Bin 中拿出相同大小 chunk 返回
在 Unsorted Bin 中若缓存过 chunk 则返回
Large Bin:选择满足大小的 chunk 中最小的,由链表头开始遍历,若有相同大小的 chunk 则用第 2 个,能拆则拆
根据 bitmap 在更大的 Bin 中搜索,
从 Top chunk 分割
_int_free
tcache:未满则放入 tcache
Fast Bin 头插
不是 mmap 分配则尝试合并
mmap 分配则 ummap -
ptmalloc2 changelog
2.23
2.24
2.25
New
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* Same, except also perform an argument and result check. First, we check that the padding done by request2size didn't result in an integer overflow. Then we check (using REQUEST_OUT_OF_RANGE) that the resulting size isn't so large that a later alignment would lead to another integer overflow. */ #define checked_request2size(req, sz) \ ({ \ (sz) = request2size (req); \ if (((sz) < (req)) \ || REQUEST_OUT_OF_RANGE (sz)) \ { \ __set_errno (ENOMEM); \ return 0; \ } \ })
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ typedefstructtcache_entry { structtcache_entry *next; /* This field exists to detect double frees. */ structtcache_perthread_struct *key; } tcache_entry; /* 有删节 */ /* Caller must ensure that we know tc_idx is valid and there's room for more chunks. */ static __always_inline void tcache_put(mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *) chunk2mem (chunk); assert (tc_idx < TCACHE_MAX_BINS);
/* Mark this chunk as "in the tcache" so the test in _int_free will detect a double free. */ e->key = tcache;
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect (misaligned_chunk (p), 0)) malloc_printerr ("free(): invalid pointer"); /* We know that each chunk is at least MINSIZE bytes in size or a multiple of MALLOC_ALIGNMENT. */ if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size))) malloc_printerr ("free(): invalid size");
check_inuse_chunk(av, p);
#if USE_TCACHE { size_t tc_idx = csize2tidx (size); if (tcache != NULL && tc_idx < mp_.tcache_bins) { /* Check to see if it's already in the tcache. */ tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100% trust it (it also matches random payload data at a 1 in 2^<size_t> chance), so verify it's not an unlikely coincidence before aborting. */ if (__glibc_unlikely (e->key == tcache)) { tcache_entry *tmp; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = tmp->next) if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ }
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ typedefstructtcache_entry { structtcache_entry *next; } tcache_entry; /* 有删节 */ /* Caller must ensure that we know tc_idx is valid and there's room for more chunks. */ static __always_inline void tcache_put(mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *) chunk2mem (chunk); assert (tc_idx < TCACHE_MAX_BINS); e->next = tcache->entries[tc_idx]; tcache->entries[tc_idx] = e; ++(tcache->counts[tc_idx]); } /* 有删节 */ staticvoid _int_free (mstate av, mchunkptr p, int have_lock) { /* 有删节 */ size = chunksize (p);
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect (misaligned_chunk (p), 0)) malloc_printerr ("free(): invalid pointer"); /* We know that each chunk is at least MINSIZE bytes in size or a multiple of MALLOC_ALIGNMENT. */ if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size))) malloc_printerr ("free(): invalid size");
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */
/* remove from unsorted list */ if (__glibc_unlikely (bck->fd != victim))//此处有改动 malloc_printerr ("malloc(): corrupted unsorted chunks 3"); unsorted_chunks (av)->bk = bck; bck->fd = unsorted_chunks (av);
/* Take now instead of binning if exact fit */
if (size == nb) { set_inuse_bit_at_offset (victim, size); if (av != &main_arena) set_non_main_arena (victim); #if USE_TCACHE /* Fill cache first, return to user only if cache fills. We may return one of these chunks later. */ if (tcache_nb && tcache->counts[tc_idx] < mp_.tcache_count) { tcache_put (victim, tc_idx); return_cached = 1; continue; } else { #endif check_malloced_chunk (av, victim, nb); void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; #if USE_TCACHE } #endif } /* place chunk in bin */
/* maintain large bins in sorted order */ if (fwd != bck) { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert (chunk_main_arena (bck->bk)); if ((unsignedlong) (size) < (unsignedlong) chunksize_nomask (bck->bk)) { fwd = bck; bck = bck->bk;
#if USE_TCACHE /* If we've processed as many chunks as we're allowed while filling the cache, return one of the cached ones. */ ++tcache_unsorted_count; if (return_cached && mp_.tcache_unsorted_limit > 0 && tcache_unsorted_count > mp_.tcache_unsorted_limit) { return tcache_get (tc_idx); } #endif
#define MAX_ITERS 10000 if (++iters >= MAX_ITERS) break; }
if (__glibc_unlikely (e->key == tcache)) { tcache_entry *tmp; size_t cnt = 0; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = REVEAL_PTR (tmp->next), ++cnt) { if (cnt >= mp_.tcache_count) malloc_printerr ("free(): too many chunks detected in tcache"); if (__glibc_unlikely (!aligned_OK (tmp))) malloc_printerr ("free(): unaligned chunk detected in tcache 2"); if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
if (__glibc_unlikely (e->key == tcache)) { tcache_entry *tmp; size_t cnt = 0; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = REVEAL_PTR (tmp->next), ++cnt) { if (cnt >= mp_.tcache_count) malloc_printerr ("free(): too many chunks detected in tcache"); if (__glibc_unlikely (!aligned_OK (tmp))) malloc_printerr ("free(): unaligned chunk detected in tcache 2"); if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ } }
New:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
if (__glibc_unlikely (e->key == tcache_key)) { tcache_entry *tmp; size_t cnt = 0; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = REVEAL_PTR (tmp->next), ++cnt) { if (cnt >= mp_.tcache_count) malloc_printerr ("free(): too many chunks detected in tcache"); if (__glibc_unlikely (!aligned_OK (tmp))) malloc_printerr ("free(): unaligned chunk detected in tcache 2"); if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
if (__glibc_unlikely (e->key == tcache_key)) { tcache_entry *tmp; size_t cnt = 0; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = REVEAL_PTR (tmp->next), ++cnt) { if (cnt >= mp_.tcache_count) malloc_printerr ("free(): too many chunks detected in tcache"); if (__glibc_unlikely (!aligned_OK (tmp))) malloc_printerr ("free(): unaligned chunk detected in tcache 2"); if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ } }
If the end of the directory stream is reached, NULL is returned and errno is not changed. If an error occurs, NULL is returned and errno is set appropriately. To distinguish end of stream from an error, set errno to zero before calling readdir() and then check the value of errno if NULL is returned.
optstring is a string containing the legitimate option characters. If such a character is followed by a colon, the option requires an argument, so getopt() places a pointer to the following text in the same argv-element, or the text of the following argv-element, in optarg. Two colons mean an option takes an optional arg
if there is text in the current argv-element (i.e., in the same word as the option name itself, for example, −oarg), then it is returned in optarg, otherwise optarg is set to zero. This is a GNU extension.
If optstring contains W followed by a semicolon, then −W foo is treated as the long option −−foo. (The −W option is reserved by POSIX.2 for implementation extensions.) This behavior is a GNU extension, not available with libraries before glibc 2.
If the first character of optstring is + or the environment variable POSIXLY_CORRECT is set, then option processing stops as soon as a nonoption argument is encountered.
If the first character of optstring is −, then each nonoption argv-element is handled as if it were the argument of an option with character code 1. (This is used by programs that were written to expect options and other argv-elements in any order and that care about the ordering of the two.)
The special argument −− forces an end of option-scanning regardless of the scanning mode.[3]
While processing the option list, getopt() can detect two kinds of errors:
an option character that was not specified in optstring
a missing option argument (i.e., an option at the end of the command line without an expected argument).
Such errors are handled and reported as follows:
By default, getopt() prints an error message on standard error, places the erroneous option character in optopt, and returns ? as the function result.
If the caller has set the global variable opterr to zero, then getopt() does not print an error message. The caller can determine that there was an error by testing whether the function return value is ?. (By default, opterr has a nonzero value.)
If the first character (following any optional + or − described above) of optstring is a colon (:), then getopt() likewise does not print an error message. In addition, it returns : instead of ? to indicate a missing option argument. This allows the caller to distinguish the two different types of errors.[3]
has_arg is: no_argument (or 0) if the option does not take an argument; required_argument (or 1) if the option requires an argument; or optional_argument (or 2) if the option takes an optional argument.
flag specifies how results are returned for a long option.
If flag is NULL , then getopt_long() returns val . (For example, the calling program may set val to the equivalent short option character.)
Otherwise, getopt_long() returns 0, and flag points to a variable which is set to val if the option is found, but left unchanged if the option is not found.
val is the value to return, or to load into the variable pointed to by flag .>The last element of the array has to be filled with zeros.[1]
如果 flag 为 NULL,getopt_only() 返回 val.(例如,调用者设置 val 为对应的短选项字符)
如果 flag 不为 NULL,getopt_only() 返回 0,并且 flag 指向的变量将被设置为 val.当未解析的该选项时,flag 指向的值不变. longopts 数组的最后一个元素需要全部字段为 0.
If longindex is not NULL, it points to a variable which is set to the index of the long option relative to longopts.[1] 如果 longinedx 不是 NULL,它指向的值将被设置为解析到的长选项在 longopt 中的索引.